gain more familiarity with the lecture contents, by repeating the analyses from the lecture yourself;
test your understanding of the model specification and interpretation, by doing similar analyses with less guidance;
explore further ideas not covered in the lecture.
There is (intentionally) more exercise material than you are likely to be able to go through during the online workshop.
All sections are independent and optional. You may pick and choose according to you interests and stop where you wish.
NOTE 1: as these exercises use large models (many parameters) fitted on a large dataset, model fitting with gam (as is done in the lecture slides) would take too long given the time we have for the practical. I therefore recommend you use the function bam instead, to fit your models. The syntax and interpretation of outputs is the same as with gam. It will just get you there faster, thanks to clever approximations that are efficient for large data sets.
NOTE 2: if one piece of code isn’t working for you, it is quite possibly because it is using an object that was created in a code that you didn’t run, further up in the practical.
Setup
We’ll first load the dataset, subset it and load the packages mgcvand maps (convenient for plotting UK contour, but not essential). And then do a bit of house-keeping, to have the variables and variable names we want.
(If you don’t have the data, you can download them from here)
try(load("cosmos-processed.RData"), silent= T)try(load("../data/cosmos-processed.RData"), silent= T)try(load("data/cosmos-processed.RData"), silent= T)# shorten response variable name (for convenience)# (We'll just make a copy, in case you prefer to stick with the long names)all_sites$VWC <- all_sites$COSMOS_VWCall_sites$LAT <- all_sites$LATITUDEall_sites$LON <- all_sites$LONGITUDE# compute "DAY OF THE YEAR" variableall_sites$doy<-as.numeric(format(all_sites$DATE_TIME, "%j"))# make a subset of Scottish datascot_sites<-subset(all_sites, SITE_NAME %in%c("Crichton", "Easter Bush", "Hartwood Home","Cochno", "Balruddery", "Glensaugh"))library(mgcv)
Loading required package: nlme
This is mgcv 1.9-0. For overview type 'help("mgcv-package")'.
library(maps)
Where did we leave the analysis?
Let’s re-fit the model from the previous exercise:
To visualise the part played by each term for predicting the data time series, we need to manually use the predict.gam function, asking for a term-specific prediction for each observation (type= "terms"), which produces a matrix of predictions with as many columns as there are terms in the model.
Note that all smooth terms in this model (and in the models we cover in this course) are centered around zero, so we need to add both the general and the site-specific intercepts to each of them, if we want meaningful scaling when plotting the predictions over the data.
The general intercept value (“constant”) is stored separately (rather inconveniently!), and can be recovered using attr(my_model_predictions, "constant") or coef(my_model)[1].
# term-specific predictions matrix (marginals)pred_b_seas<-predict(b_scot_season, type="terms")# visualise the objecthead(pred_b_seas, n=4)
# full model predictions (sum of all columns)pred_full<-apply(pred_b_seas, 1, sum) +attr(pred_b_seas, "constant")# model predictions excluding `ndate` effect (column 2)pred_notrend<-apply(pred_b_seas[, -2], 1, sum) +attr(pred_b_seas, "constant")# model predictions excluding `doy` effect (column 4)pred_noseason<-apply(pred_b_seas[, -4], 1, sum) +attr(pred_b_seas, "constant")
In case it helps understanding this model better, let’s now take it apart and plot the data (using a single site, for clarity) and the marginal predictions for that site, from different subsets of terms. Note that each set of predictions includes the random intercept for the corresponding site, again for the purpose of scaling with the data.
tip: jan1<- sort(unique(all_sites[all_sites$doy == 1, "ndate"])) gives us all the ndates that are a 1st of Jan. abline(v= jan1, col= "grey3", lty= 3) will add a vertical line at the start of each year, to facilitate the interpretation.
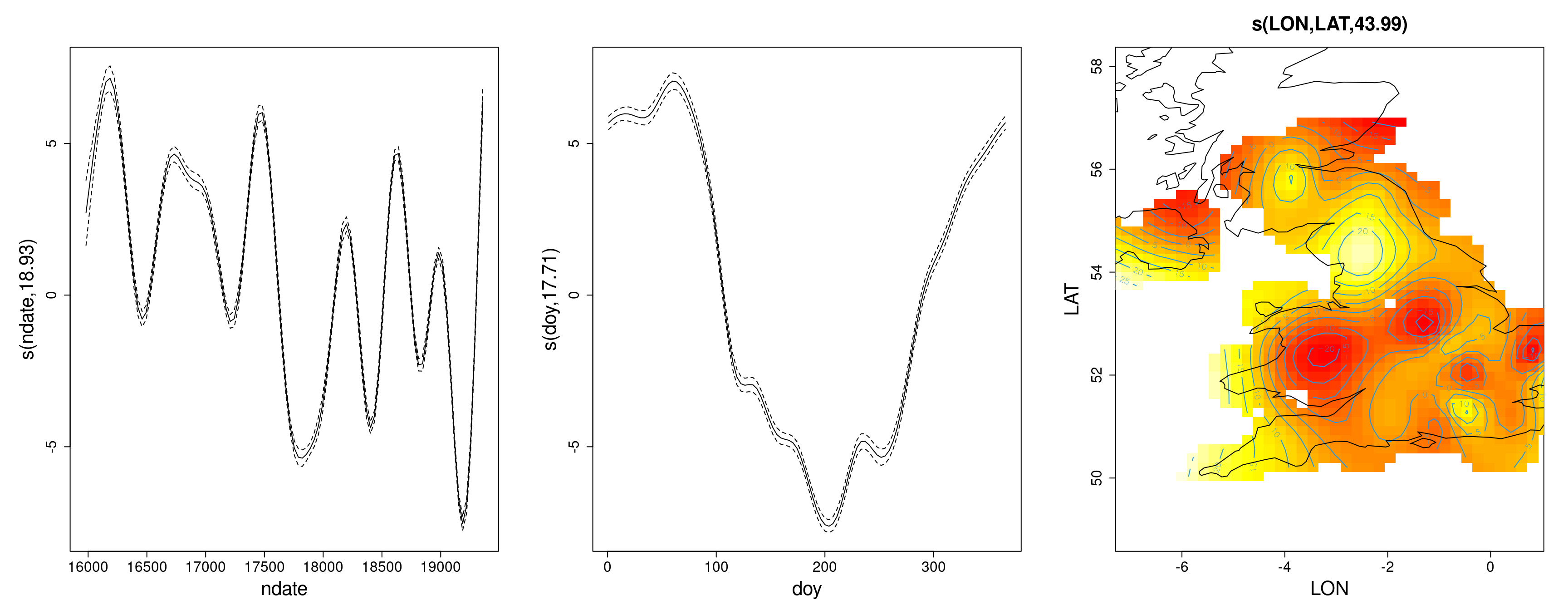
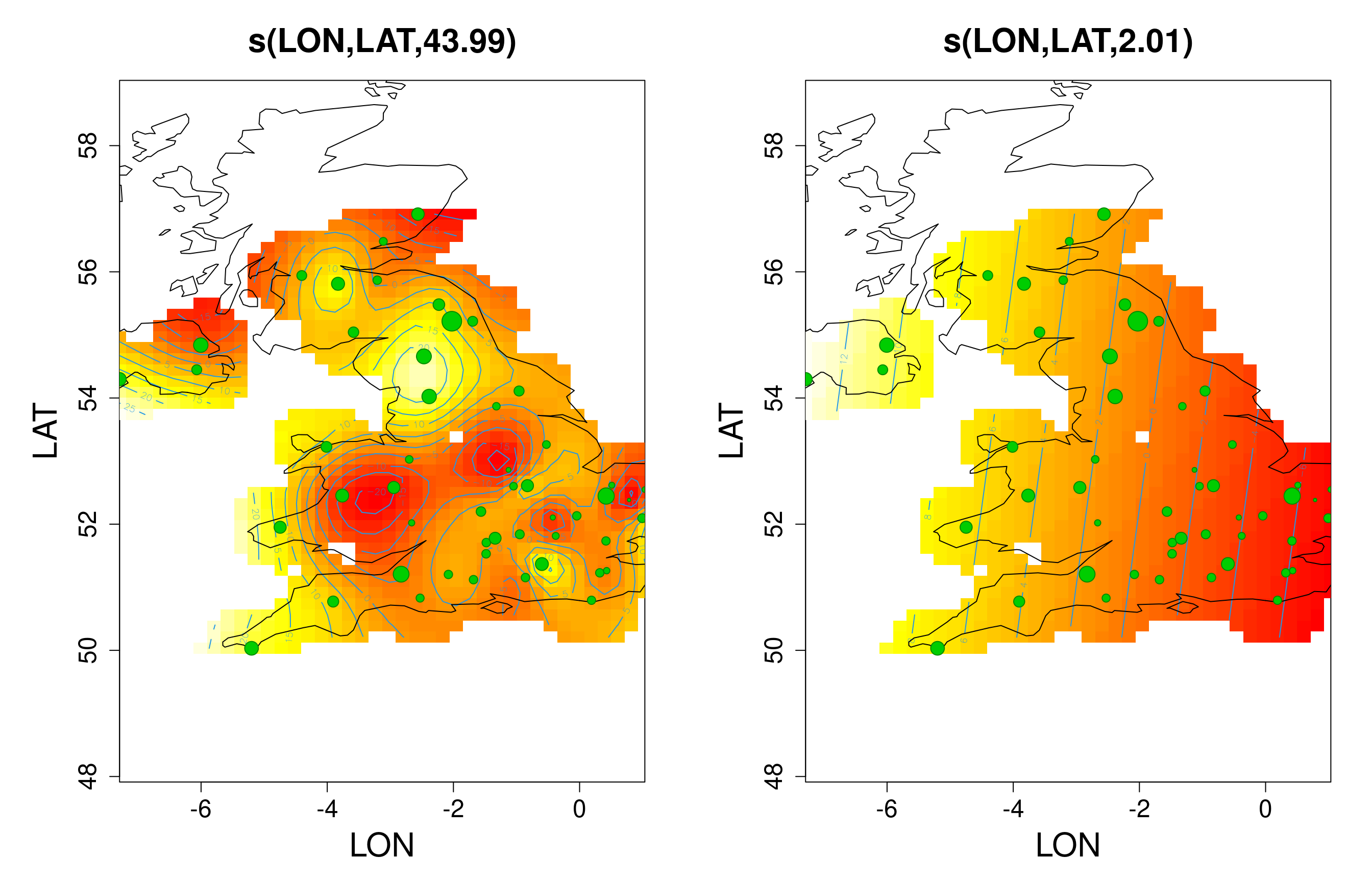
If we want to estimate the average spatial trend while accounting for (“conditional on”) average temporal trends in the data (seasonal and non-seasonal), we just need to add the spatial smooth to the model. We can set a high k value for the spatial effect, in case the true trend is complex (but has to be smaller than the number of unique sites).
Note that for the sake of demonstration, in this model I will drop the SITE_ID random effect (which we can view as a very flexible, implicitly spatial term, without an explicit spatial structure), to ensure that there is no possible confounding with the smooth, spatially-explicit (LAT,LON) trend.
Family: gaussian
Link function: identity
Formula:
VWC ~ SOIL_TYPE + s(ndate, k = 20) + s(doy, bs = "cc", k = 20) +
s(LON, LAT, k = 45)
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 30.97737 0.08416 368.07 <2e-16
SOIL_TYPEMineral soil 4.93474 0.10732 45.98 <2e-16
SOIL_TYPEOrganic soil 37.28593 0.21405 174.19 <2e-16
SOIL_TYPEOrganic soil over mineral soil 3.32671 0.29072 11.44 <2e-16
(Intercept) ***
SOIL_TYPEMineral soil ***
SOIL_TYPEOrganic soil ***
SOIL_TYPEOrganic soil over mineral soil ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Approximate significance of smooth terms:
edf Ref.df F p-value
s(ndate) 18.93 19 1913.0 <2e-16 ***
s(doy) 17.71 18 544.5 <2e-16 ***
s(LON,LAT) 43.99 44 7638.3 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
R-sq.(adj) = 0.848 Deviance explained = 84.8%
-REML = 4.1039e+05 Scale est. = 36.887 n = 127228
Was dropping the site random effect a good idea?
Think:
how many sites do we have in total?
how many edf does the smooth spatial effect account for?
how much spatial smoothing has effectively taken place, in this model?
what was the max df we allowed, for that term?
# Indeed, the complexity of the spatial term (its *edf*) # is bumping against the maximum we have set. If we increase this, # we'll soon reach the number of sites, so doing no better # than a spatially unstructured random intercept.
It’s worth noting that models can (sometimes advantageously) include both spatially structured (“spatially explicit”) and standard (i.e. spatially unstructured) random effects. The latter can be called “spatially implicit”, when the levels represent different spatial locations.
3. Does the seasonal pattern change with latitude? (space-time smoothing)
An (incorrect) approach to space-time smoothing
It is tempting to simply extend the bivariate smooths we’ve just used to model the interaction between the seasonal variation term and latitude: s(doy, LAT). k needs to be fairly high, because we want the 2D spline bases to give a good coverage of all combinations of doy and LAT. Note that k= 40 in 2D is only roughly on the order of k= sqrt(40) in 1D, which is about 6, so still not very high.
(In this model, I’ve removed the not very useful spatial trend and replaced it with the standard random SITE_ID effect)
The very odd pattern for the middle term, s(doy, LAT), is due to the fact that the s(X1, X2) function assumes isotropy, i.e. the same amount of smoothing in all directions.
Because the spatial and temporal distance units are arbitrary and not comparable in this case, this can create distorsions. Indeed, we have
LAT: 50 - 56° North (6 units range)
doy: 1 - 366 days (365 units range),
Even if the ranges looked similar, there is no expectation in principle that the same amount of smoothing should be suitable for both dimensions.
Also, multivariate s() terms force us to use the same type of smoother for all the dimensions, when what we would actually need is
a cyclic effect for doy
a non-cyclic effect for LAT.
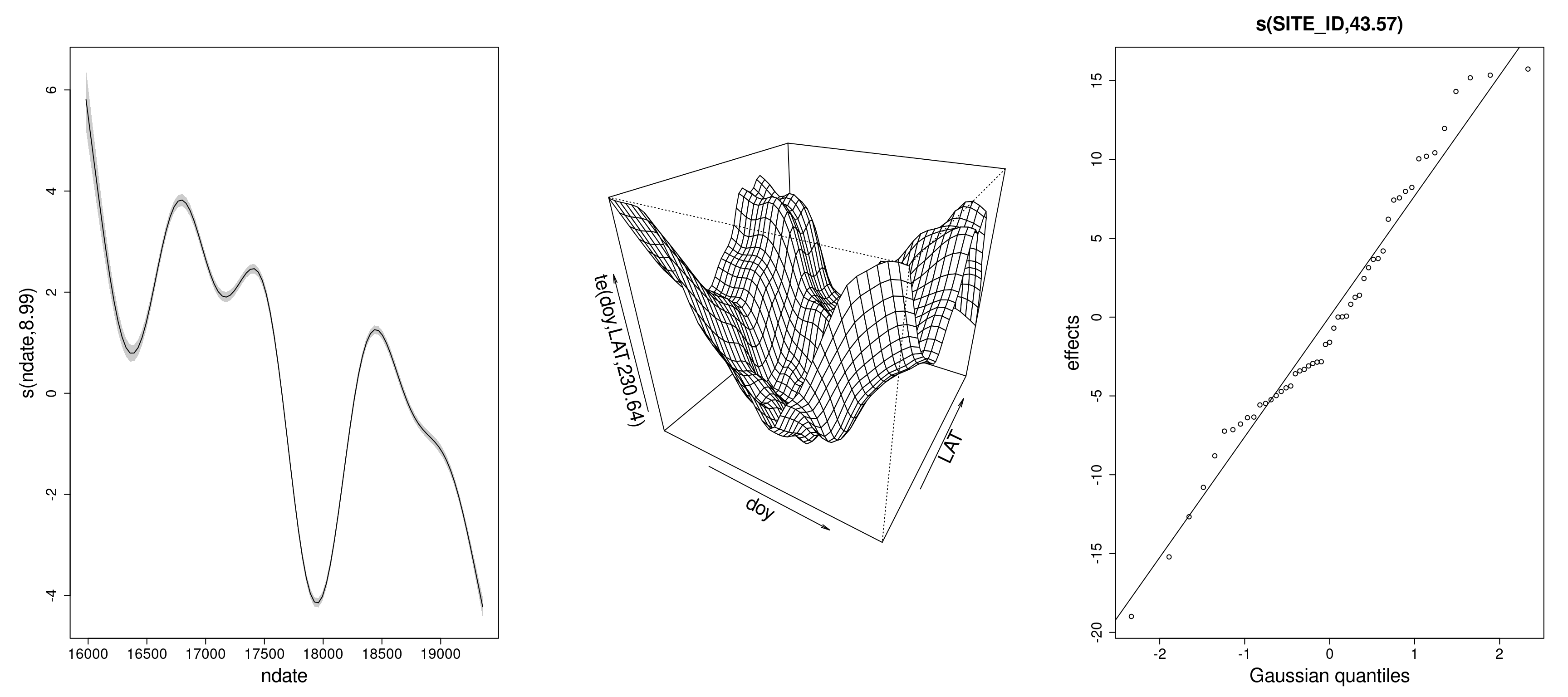
A better approach: multidimensional smoothing with anisotropic tensor product smooths
A tensor-product smooth (product of 1D splines per margin) like te(doy, LAT, bs= c("cc", "tp")), resolves the issues above, by providing:
But in multiple dimensions, interpretation can remain tricky.
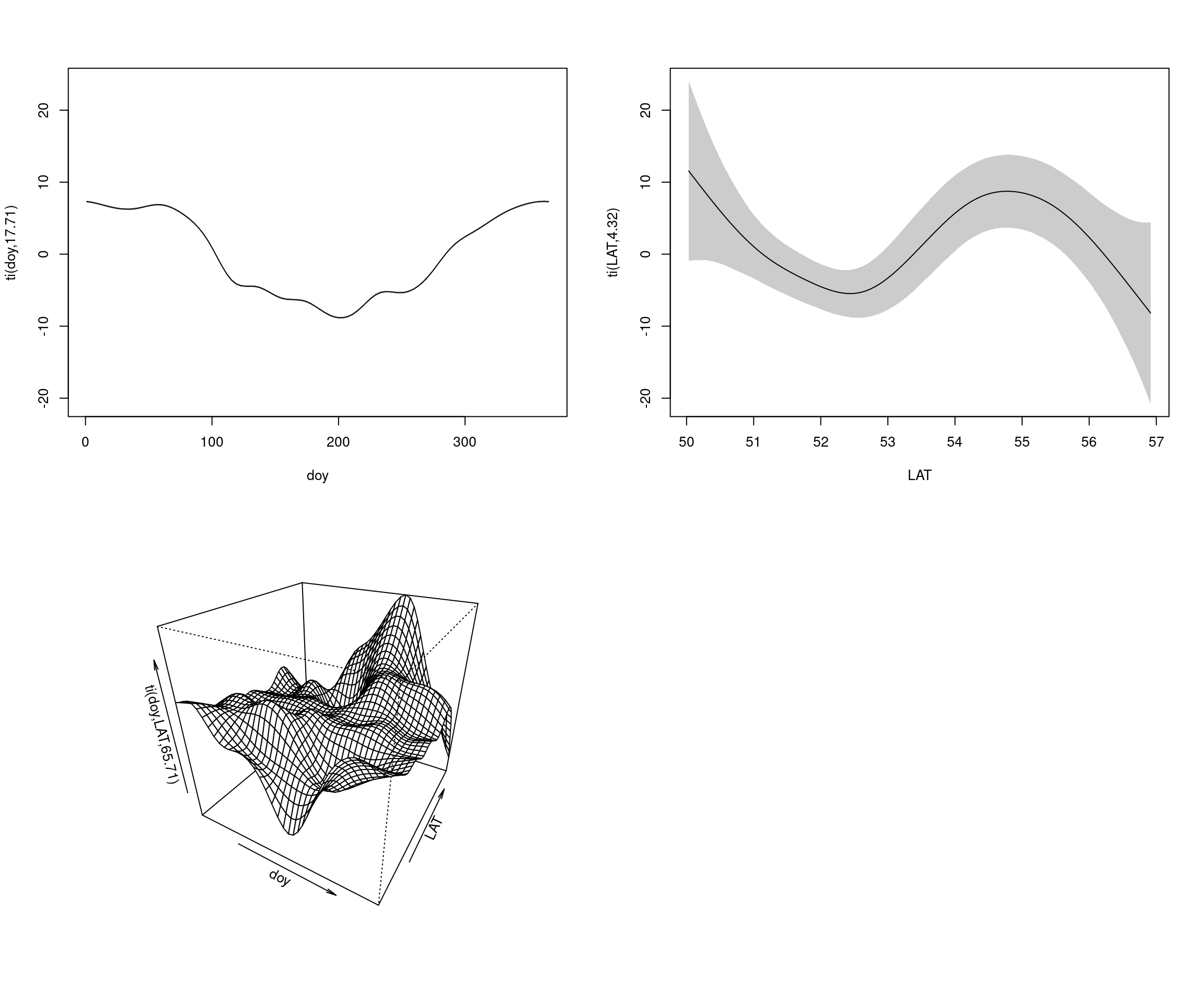
Interpreting the 3D space-time smooth
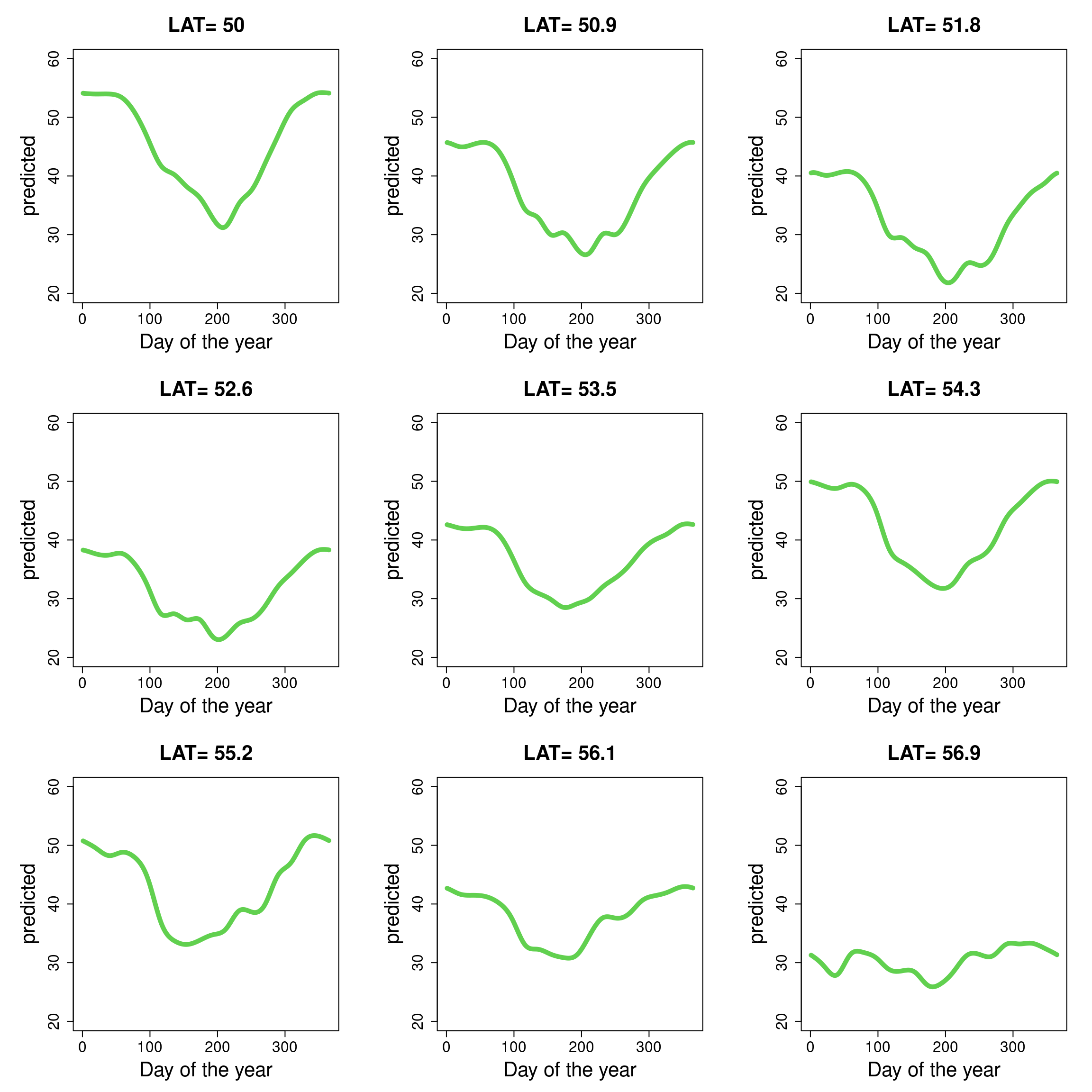
If the multidimensional object is a bit complex, an effective approach can be to slice it in meaningful ways. Here for example, predicting the seasonal trend (doy effect) for a range of set latitudes, would allow us to focus on how the seasonal trend changes up and down the country. The converse, predicting the latitudinal profile for a given time of the year, seems less useful (but this may be a useful thing to do, in some contexts).
Create a regular sequence of 9 values over the range of observed latitudes
predict the corresponding doy effect, fixing other variables c("SOIL_TYPE", "ndate", "SITE_ID") at an arbitrary value (I used values of the first observation in the data, purely for convenience)
There is a clear change in seasonality with latitude, the South being more seasonal (having much larger amplitude) than the North. The difference is most obvious at the two extreme latitudes. Sites in-between are somewhat more similar to each other, yet with idiosyncratic local variation (including in the average wetness across the whole year), likely driven by other factors.
[optional trick] Variance decomposition for nested effects
To facilitate interpreting more complex non-linear interaction terms between two or more predictors, like te(doy, LAT, bs= c("cc", "tp")), it is possible to decompose this smooth into orthogonal main effects and interaction terms, using a specially designed tensor product function, called ti.
The main effect for doy becomes ti(doy, bs= c("cc")
The main effect for LAT becomes ti(LAT, bs= c("tp")
The pure interaction part becomes ti(doy, LAT, bs= c("cc", "tp")
Plot 3 shows the interaction between doy and LAT, to be interpreted as a deviation from the marginal main effects. This leads to a similar interpretation as the “9 slices” plots just earlier:
at the lower latitudes, we see a doy effect of similar shape to the main doy effect which amplifies the seasonal trend, at low latitudes.
at the highest latitudes, we see a mirror shape which tends to cancel the seasonal trend, at high latitudes.
Beyond helping with the interpretation of the patterns in the data, the ti smooths can be particularly useful for indentifying which of these interaction components are non-zero. In contrast, the standard tensor product te only tests for the significance of the whole term (combined main effects and interaction), i.e., testing if at least one of these 3 components is non-zero.
Exercises
Testing your familiarity
Try working through the above using a different set of predictors of your choice.
Remember to reflect on model outputs:
what does the model summary, including p-values, edf and ref.df tell us? Does everything look plausible?
what do the model plots mean and what inference can we draw from them?
[Recommended - extra thinking]
Can you make sense of how the different model components (terms) work together?
Are the usual model checks (e.g. gam.check) looking okay for your models?
Additionally, you could look for residual temporal autocorrelation using acf(residuals(my_model)). Is there any? If so, what may the implications be?
Multivariate smooths
Which predictors might make sense to include as part of multivariate smooths?
For those, could/would you use s() or te()?
[Optional - extra experimenting]
You may want to play with different options for arguments bs and k, to experiment and see what works or doesn’t, and reflect on what may or may not make sense based on your own domain expertise.
for k, see examples from the lecture. More info in ?s and ?te
for bs, best to play with either “cc” or “tp”. If curious about alternative options, see ?smooth.terms. But beware: it’s a rabbit hole and we won’t have time in this course to explore or discuss much of the possible options!
[Optional - extra thinking] Spatial trend + random effects
We could fit a model with both the spatially explicit trend and the random SITE_ID intercept (spatially implicit, unstructured)
What difference does this make? Does it make sense?
(Unfold code below, for some thoughts on the problem)
Code
# Average wetness at a location is a combination of spatially # structured variation (caused by predictors varying at # large-scale) and spatially unstructured variation (caused # by site-specific variation or by predictors varying at # scales smaller than the distance between our sites). # The model with random effects is able to capture both spatially # structured and unstructured variation, and suggests both types # are supported by the data, making this model likely more # appropriate and useful.
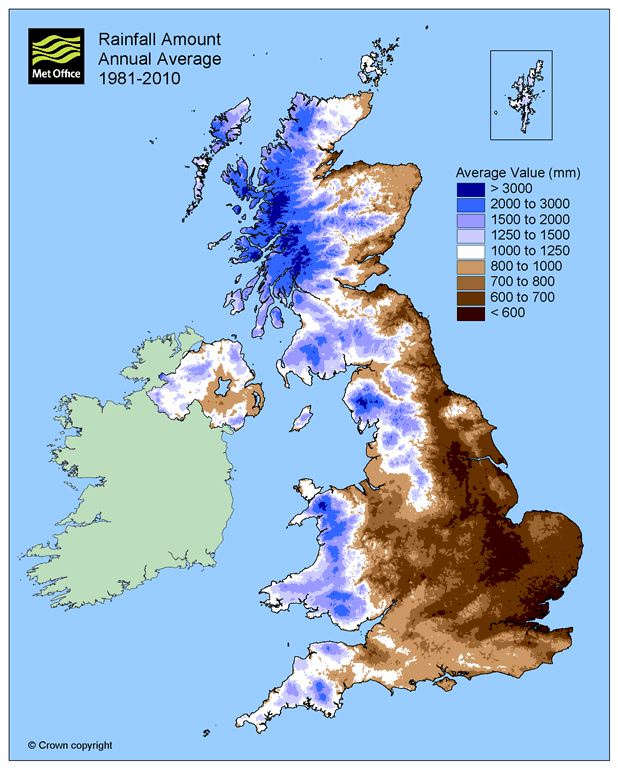
Contrast the estimated spatial trends above with the average annual rainfall over the UK
Cyclic smoothers
Try fitting a seasonal model with a different time variable, like the week or month of the year.
Does that make any difference compared to using doy?
[Optional - extra thinking] Interplay between constrained vs. more flexible smooths #1
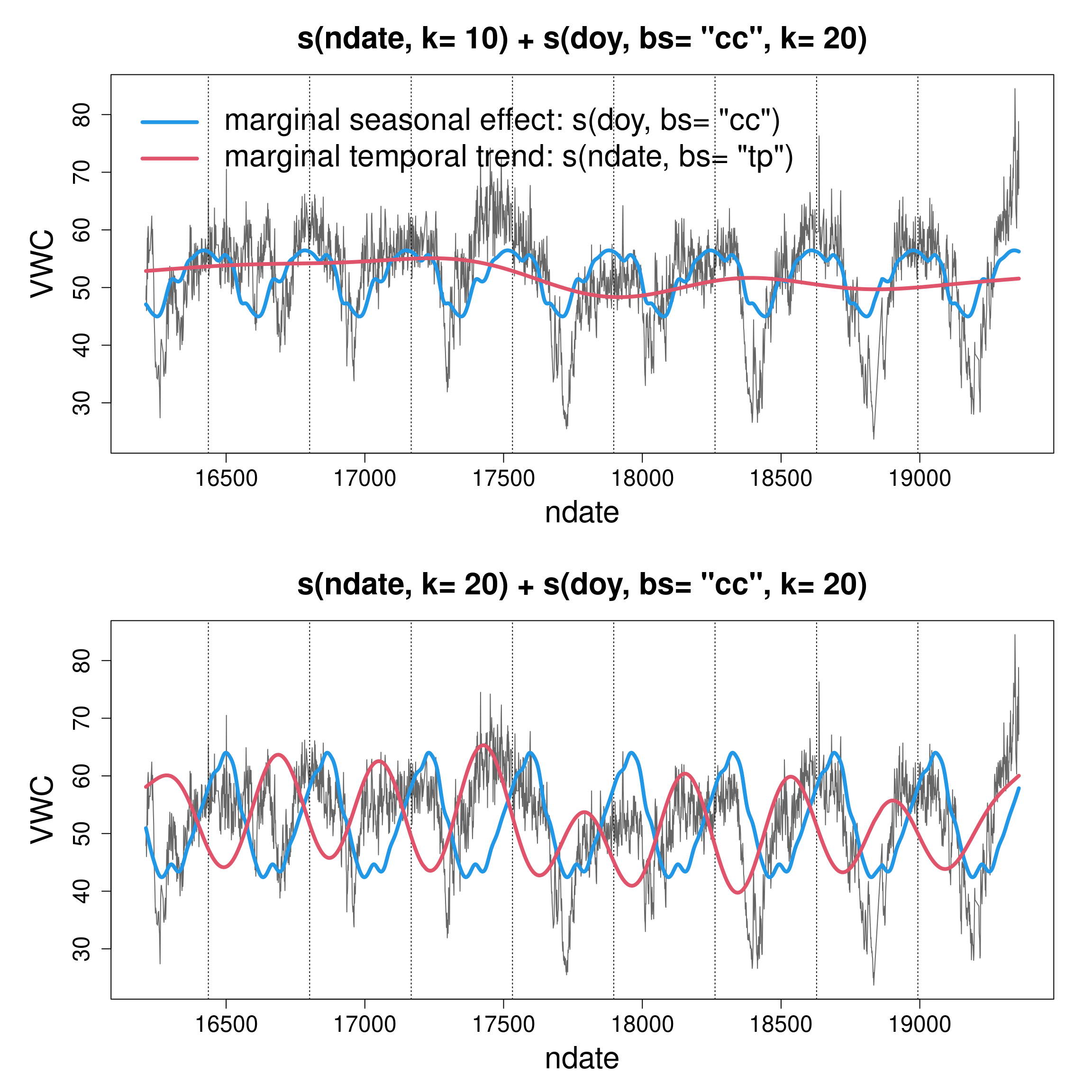
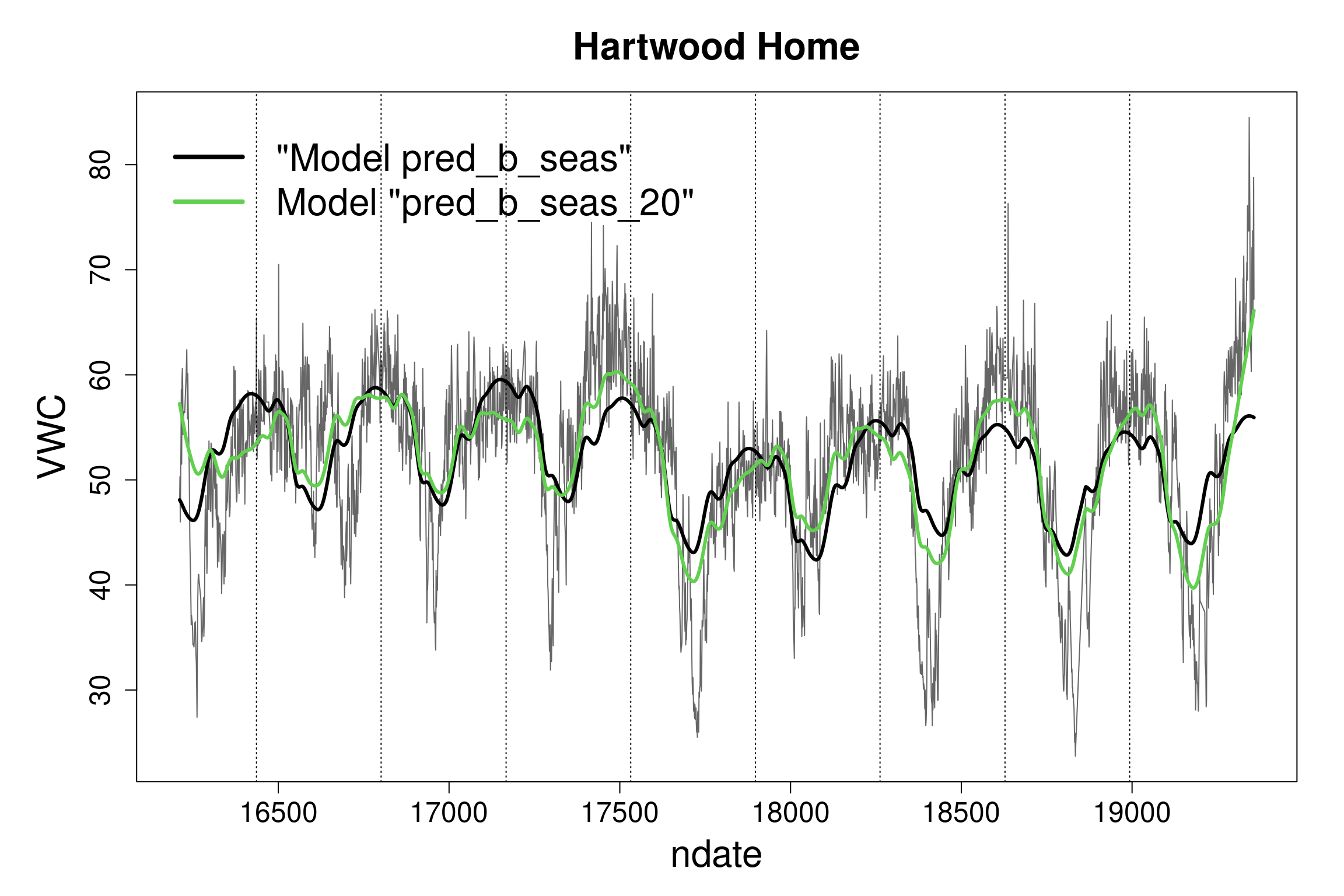
I left the k value for the s(ndate) term a bit low, in the model b_scot_season. Almost certainly too low, as the estimated edf is up against the maximum possible (10 by default, but ref.df also gives us an approximate idea of what that is).
How about repeating the analysis and pushing k up, for example at 20?
how does this change the results, including the term-specific fits?
can you explain what happened?
tip: jan1<- sort(unique(all_sites[all_sites$doy == 1, "ndate"])) gives us all the ndates that are a 1st of Jan. abline(v= jan1, col= "grey3", lty= 3) will add a vertical line at the start of each year, to facilitate the interpretation.
(Unfold code below, for some thoughts on the problem)
Code
# In the original model, the s(doy, bs= "cc") term picks # what looks like repeatable patterns year-on-year in the # data, while the s(ndate, bs= "tp", k= 10) term picks any # remaining temporal term. # The rest goes into the residual variation.# In the second model, the term s(ndate, bs= "tp", k= 20) # has much more flexibility to pick-up temporal trends that # are not repeatable year-on-year. Looking at the bottom # panel suggests that VWC in autumn (red peaks) is much # more variable year-on-year than late winter-spring # VWC (red throughs). The `ndate` term now has the ability # to pick some of this variation, which as a result gets # taken away from the periodic `doy` term.
And a plot of the overall predictions of the two models.
(Unfold code below, for some thoughts on the problem)
Code
# Predictions are still relatively close, as some of the # variation has just been transfered from one term (and from # the residuals) to another. # But they are somewhat different, as we would expect from # the latter model having more flexibility overall.
What would happen if you push k very high, e.g. 100?
which of these models would you keep?
why?
[optional follow-on - overthinking] Interplay between constrained vs. more flexible smooths #2
Sticking with the scot_sites data and function bam,
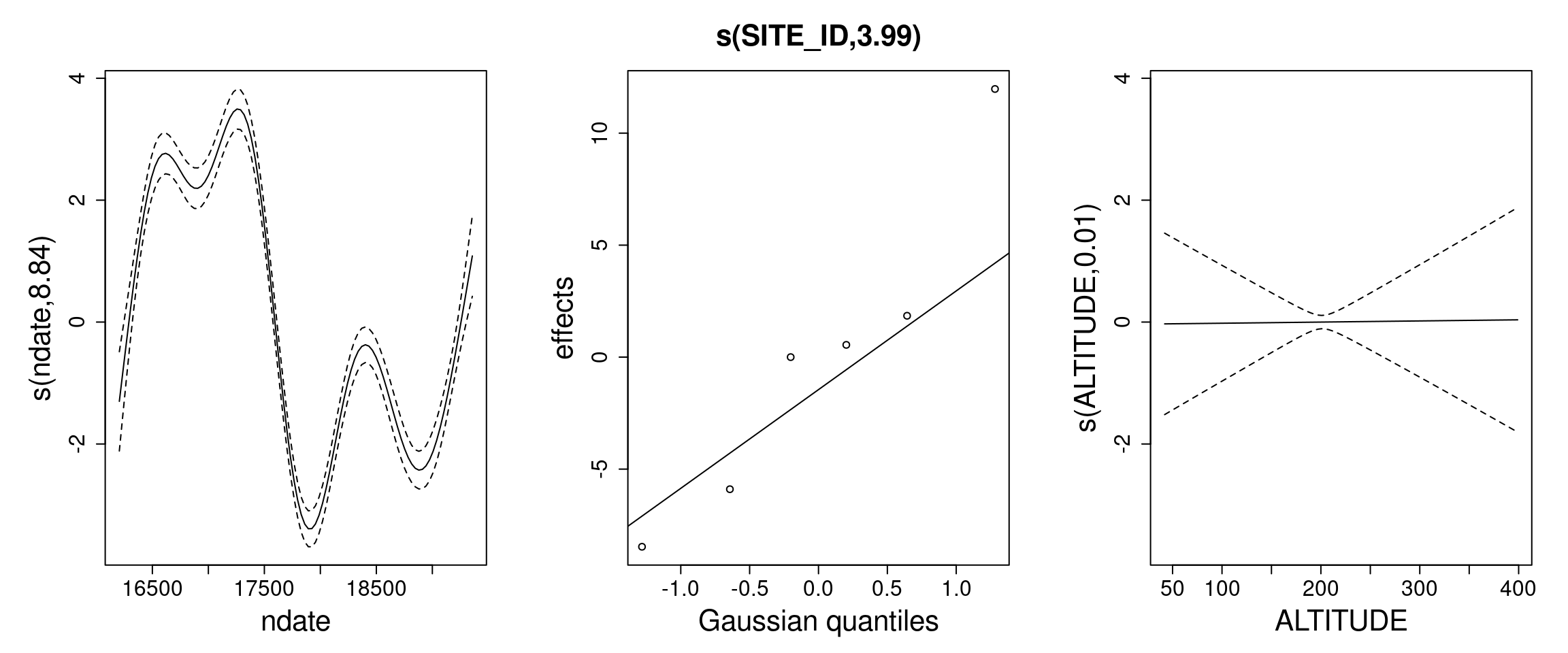
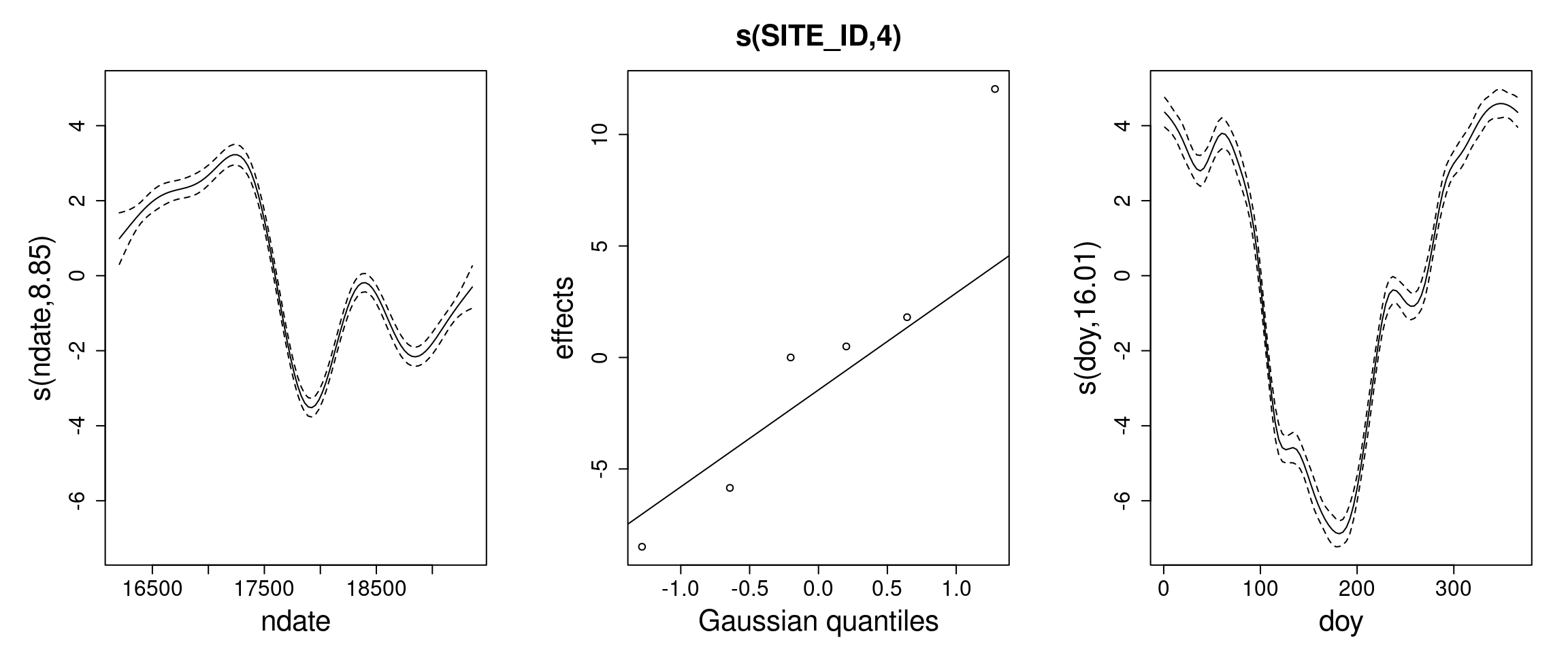
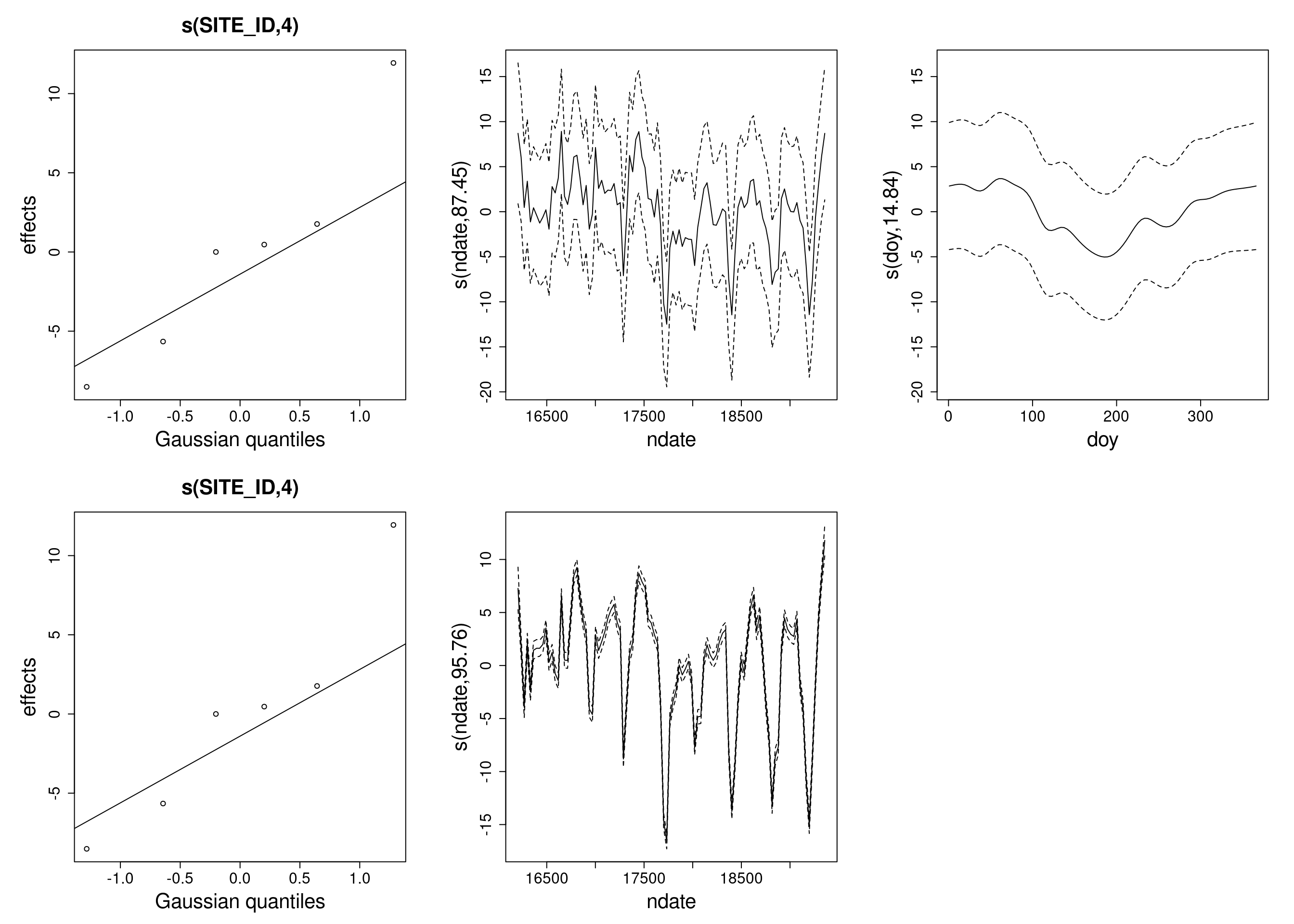
# Plots of fitted terms (1 row per model)par(mfrow=c(2, 3), mar=c(5.1, 6.1, 4.1, 2.1),cex.axis=1.5, cex.lab=2, cex.main=2)plot(b_hart_season_100)plot(b_hart_100)
(Unfold code below, for some thoughts on the problem)
Code
# The seasonal model has a highly significant seasonal term still.# The `s(ndate)` fit in the seasonal and the non-seasonal model # bear some resemblance but the credible intervals are narrower # in the non-seasonal model.
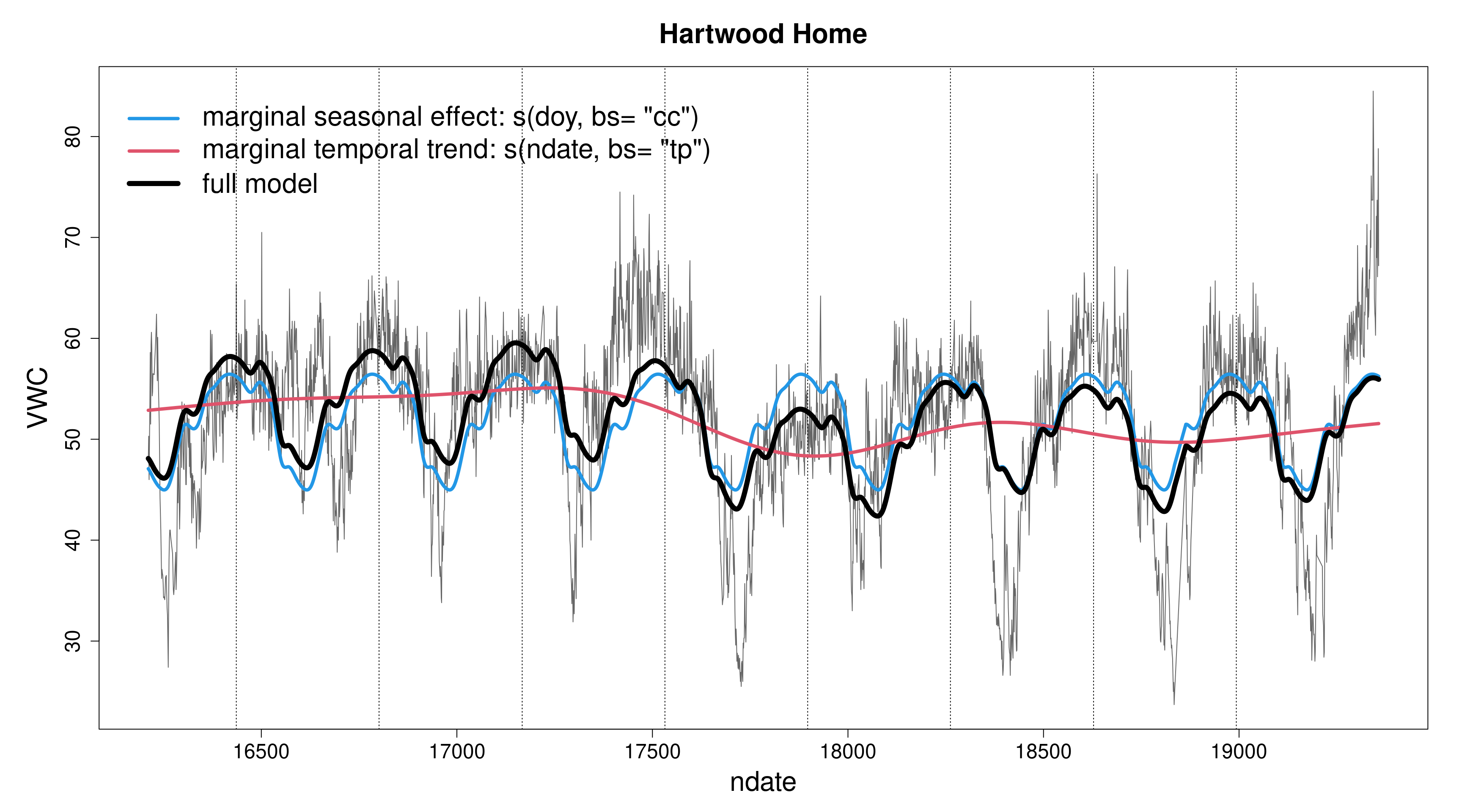
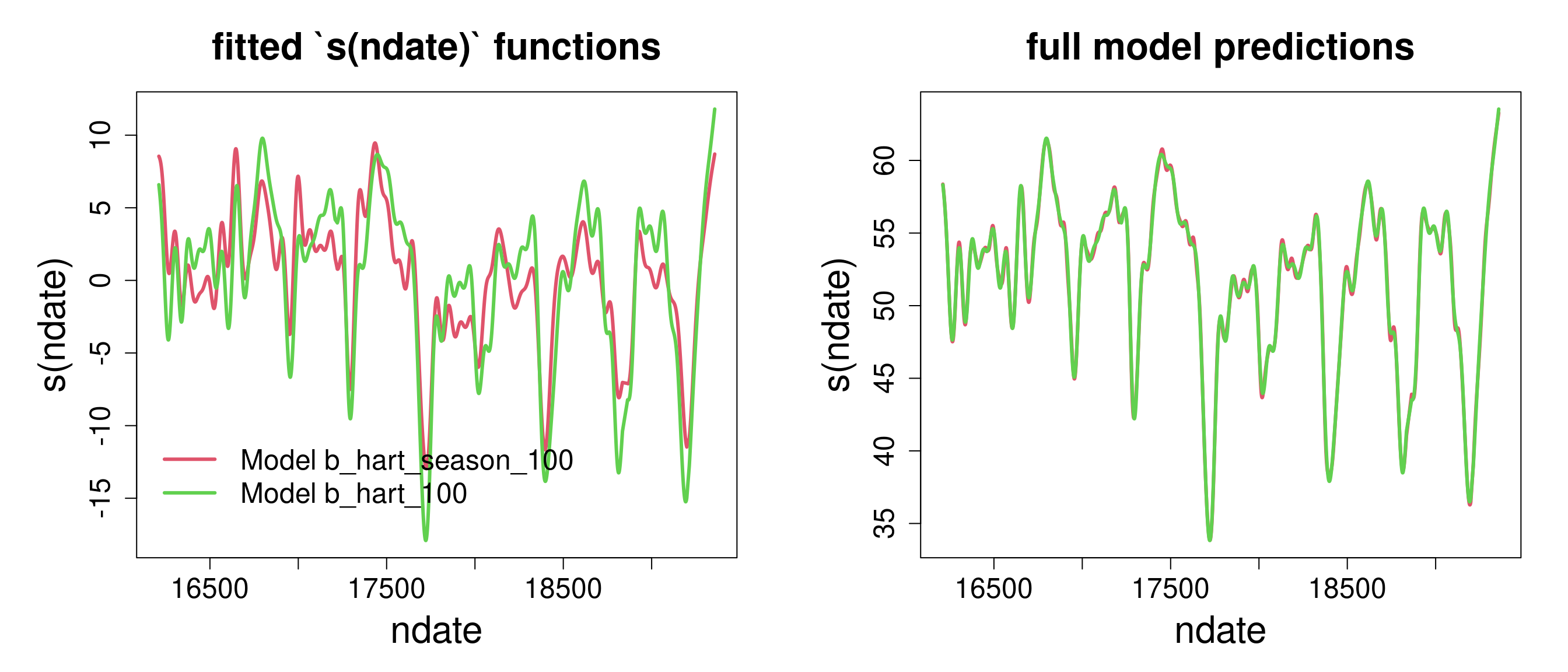
Plotting the fitted s(ndate) functions (left) and the full model predictions (right), for the “Hartwood Home” site:
(Unfold code below, for some thoughts on the problem)
Code
# In the seasonal model, the s(doy, bs= "cc") term picks the # repeatable patterns year-on-year in the data, while the # less constrained `s(ndate, bs= "tp", k= 100)` term picks # any "left-over" temporal variation. # In the non-seasonal version, because the s(ndate, bs= "tp", k= 100) # has so much flexibility, it is able to capture the two # types of temporal variation at once.# The overall model predictions are almost identical, and as # a result, so are the R^2 values. In effect, the seasonal # variation has just transferred to the s(ndate) term.# Interestingly,# 1. By manipulating the structure of the model and the # constraints on the terms, such as smoothness or cyclicity, # the analyst can effectively decompose the variation in # the data, to focus on structures of interest (for example, # the seasonal component of variation, here)# 2. This example illustrate how measures of fit such as # R^2 (or even AIC) may of very limited unsefulness for # comparing models, in cases where the model is very # flexible, descriptive, and marginal changes in model # structure may simply be bouncing a roughly constant # amount of explained variation across terms.# 3. When the less constrained `s(ndate)` term is given # sufficient flexibility, it becomes effectively # "interchangeable" with `s(doy)`. # This confounding / collinearity (also called "concurvity" # in GAM) explains the inflation of the credible intervals # in the seasonal model.