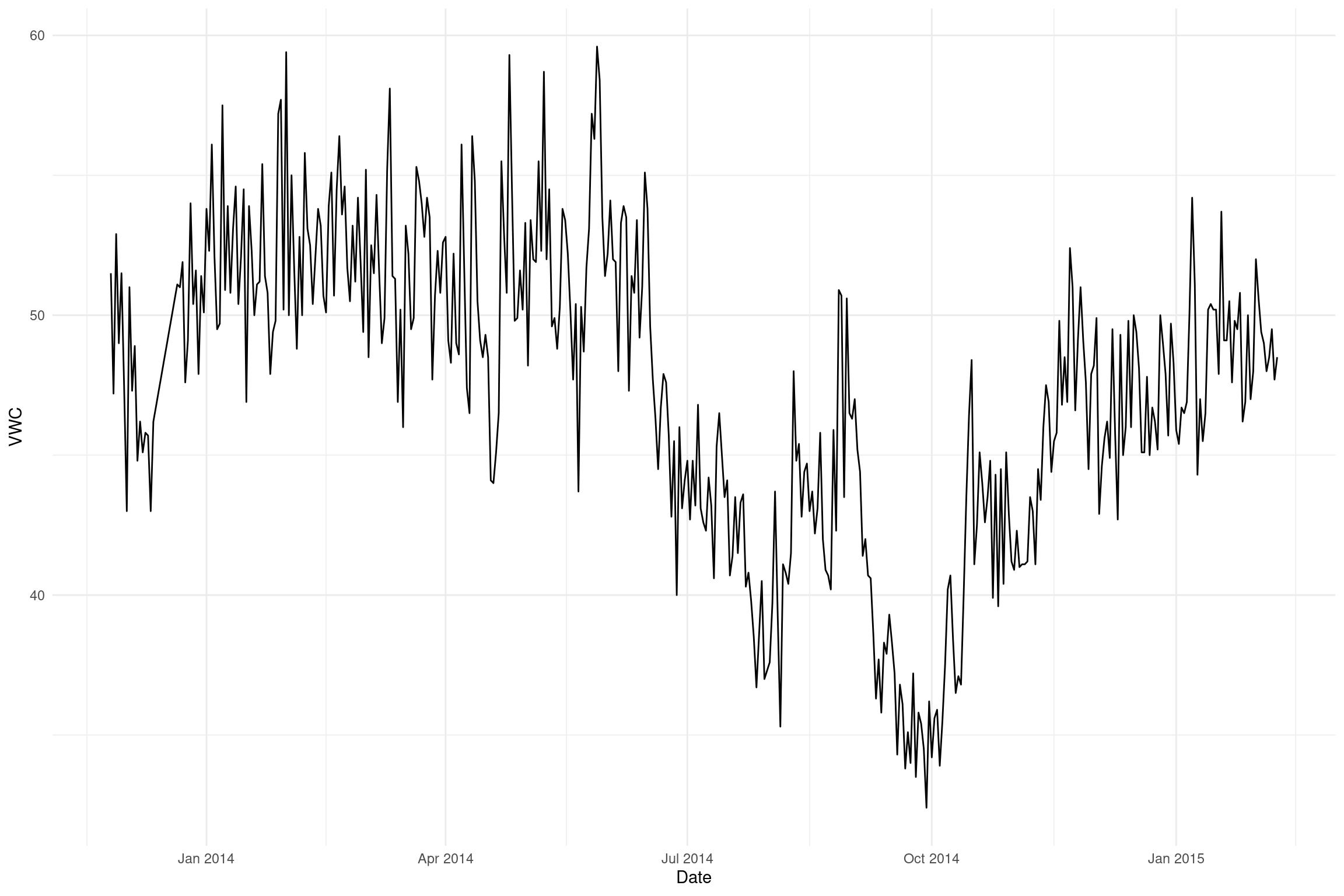In this practical exercise we’ll look at fitting a very simple model to our data, as well as look at basic exploratory plots.
The data
We will use the COSMOS-UK soil moisture data at a daily resolution. We’ve already downloaded all of the data and pre-processed it for the exercise. You can find the original data here and our processing code here.
The measurement we’re interested in here is the “volumetric water content” (VWC) as a function of other covariates such as space and time. VWC is derived from counts of fast neutrons in the surrounding area by a cosmic-ray sensing probe.
Let’s take a look (if you don’t have the data, you can download it from here:
load("cosmos-processed.RData")head(all_sites)
SITE_ID SITE_NAME LONGITUDE LATITUDE NORTHING EASTING ALTITUDE
1 ALIC1 Alice Holt -0.858232 51.15355 139985 479950 80
2 ALIC1 Alice Holt -0.858232 51.15355 139985 479950 80
3 ALIC1 Alice Holt -0.858232 51.15355 139985 479950 80
4 ALIC1 Alice Holt -0.858232 51.15355 139985 479950 80
5 ALIC1 Alice Holt -0.858232 51.15355 139985 479950 80
6 ALIC1 Alice Holt -0.858232 51.15355 139985 479950 80
LAND_COVER SOIL_TYPE DATE_TIME PRECIP SNOW_DEPTH COSMOS_VWC ndate
1 Broadleaf woodland Mineral soil 2015-03-07 0.0 NA 40.8 16501
2 Broadleaf woodland Mineral soil 2015-03-08 0.0 NA 42.9 16502
3 Broadleaf woodland Mineral soil 2015-03-09 0.1 NA 38.8 16503
4 Broadleaf woodland Mineral soil 2015-03-10 0.0 NA 45.9 16504
5 Broadleaf woodland Mineral soil 2015-03-11 0.0 NA 39.7 16505
6 Broadleaf woodland Mineral soil 2015-03-12 0.0 NA 42.1 16506
month year
1 3 2015
2 3 2015
3 3 2015
4 3 2015
5 3 2015
6 3 2015
The columns have the following meanings:
SITE_ID short-form site identifier
SITE_NAME long site name
LONGITUDE unprojected coordinate
LATITUDE unprojected coordinate
NORTHING Northing, projected according to the Ordnance Survey National Grid
EASTING Easting, projected according to the Ordnance Survey National Grid
ALTITUDE altitude of the site
LAND_COVER what land cover classification was at the site
SOIL_TYPE the soil type at the site
DATE_TIME the date of the sample
PRECIP recorded precipitation
SNOW_DEPTH recorded snow depth
COSMOS_VWC volumetric water content
ndate observation date converted to numeric
month month of observation
year year of observation
For this first exercise we will ignore most of the variables and concentrate on a single site at a single time. Before we do that let’s just reproduce the plots from the slides.
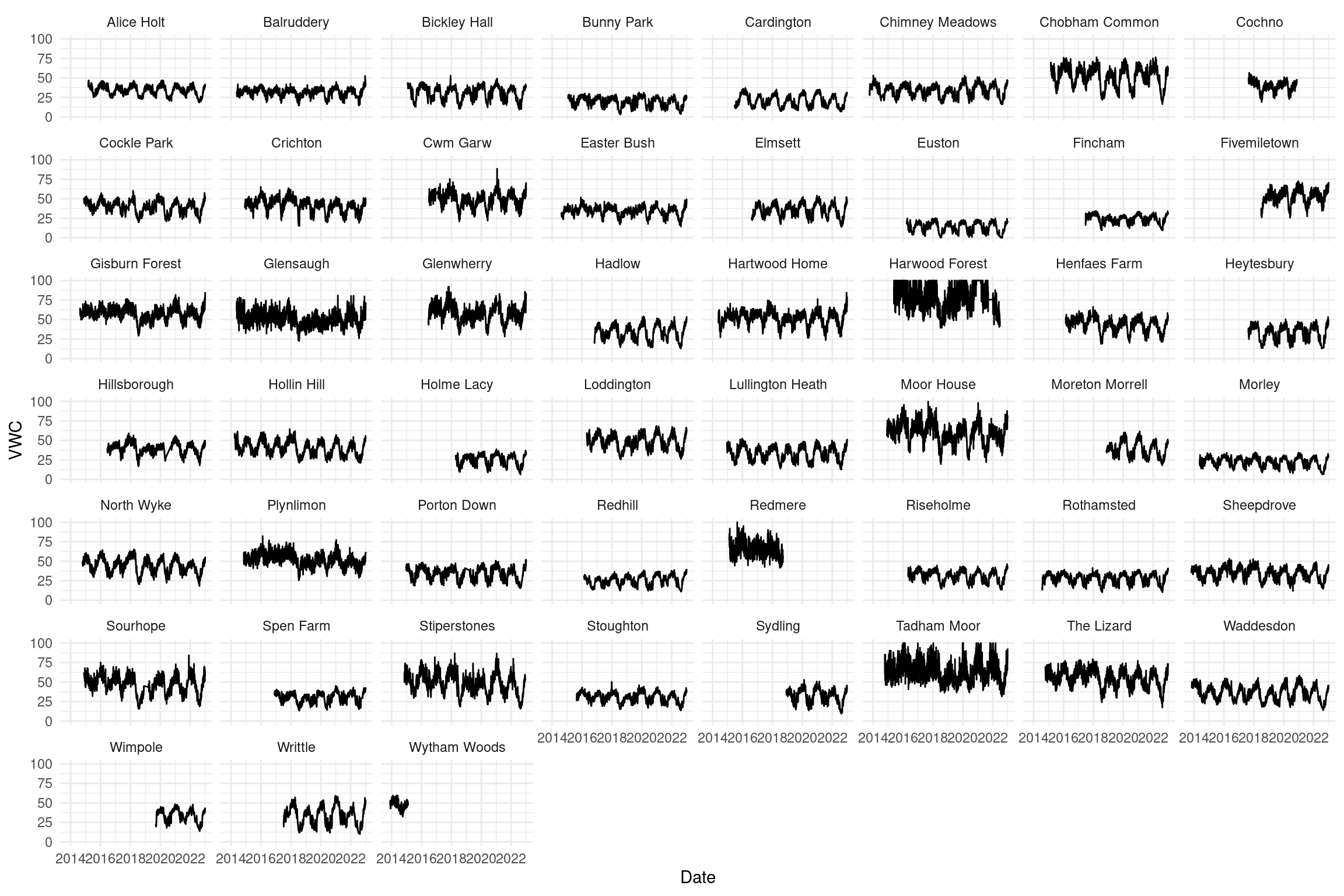
This is the full data set as a time series per site:
Note that some sites have a much longer time series than others. We’re just going to use the shortest series “Wytham Woods” as an example here.
Temporal modelling of Wytham Woods
We need to subset the data to include only the Wytham Woods observations and create a new data.frame for those observations. We can then plot the time series for Wytham Woods alone:
To fit our first simple model, we need to load the mgcv package. I’d recommend making sure that you have the latest version installed (mgcv is installed with R, so you’ll always have a copy, just not necessarily the latest version). We can make sure we have the latest version by running:
update.packages("mgcv")
We can then load the package:
library(mgcv)
Loading required package: nlme
This is mgcv 1.9-0. For overview type 'help("mgcv-package")'.
So, let’s start by fitting a simple smooth of time to our model. We have the DATE_TIME column in our data, however mgcv doesn’t know how to deal with date bjects, so we use the ndate column, which is simply the numeric versions of those dates.
We know we want COSMOS_VWC as the response and ndate to be our explanatory variable. Mathematically, our model looks like this:
b <-gam(COSMOS_VWC ~s(ndate), data=wwoods, method="REML")
Note the following in the model construction:
Our formula looks very similar in maths and in code. We don’t have to specify the intercept term, it’s always there by default (just like with lm() and glm()).
We don’t specify a response distribution, we just rely on the default. Implicitly we are fitting this model with family=gaussian().
We use method="REML", this uses restricted maximum likelihood to estimate the model parameters. There has been a fair amount of theoretical and practical work showing this method performs well. It’s best to stick with this option for now.
We can then interogate the object as we normally would with a model output:
As mentioned in the lecture, the output of summary() has a lot of information in it. We can see details of the model that we fitted in terms of the options that we set and in terms of estimated model parameters.
Some highlights from top to bottom:
At the very top we can see that the response distribution was Gaussian (Family: gaussian) and that the link used was the identity.
We see the formula we gave for the mean effect
We then have a table of parametric coefficients, these are the things that are like a linear model: intercepts and slopes. In this case we just have the intercept, and the output gives the estimate as well as its standard error, the test statistic and result for the t-test that it is zero.
After the parametric coefficients, we have the smooth terms. Here we have one row per term and since we don’t care about the individual parameter estimates, we just have the effective degrees of freedom (edf) as the quantity of interest. We then have test statistics and results from the test that the smooth has zero effect (that it’s not significantly different from zero). Note that the default basis size (k) is 10, so our EDF is relatively close to that.
The penultimate line has rough statistics for explanatory power of the model: the R^2 and the percentage deviance explained.
Finally we have the negative REML score, the estimate of \sigma^2 and the sample size.
Checking the basis size
We can see how big the basis size is relative to the EDF by using gam.check(). Note that this function will produce some plots (which I’ve suppressed in this document) that we will look at more closely later.
gam.check(b)
Method: REML Optimizer: outer newton
full convergence after 7 iterations.
Gradient range [-3.367285e-07,8.300716e-08]
(score 1150.533 & scale 10.2183).
Hessian positive definite, eigenvalue range [3.13693,219.0595].
Model rank = 10 / 10
Basis dimension (k) checking results. Low p-value (k-index<1) may
indicate that k is too low, especially if edf is close to k'.
k' edf k-index p-value
s(ndate) 9.00 8.17 0.5 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
We can usually ignore the first paragraph above, and concentrate on the table. In this table we have a row for each smooth in the model. Listed is the k', which is the basis size used for this term. Note that here although the k we supplied to s() was 10 (by default), k' here is 9. That’s because in the 10 we specified, there was also an intercept term to be estimated. We have that as a global term in the model, so we need to remove it from each individual term (you can imagine the issues if we had 3 intercepts in the model – the model would not be identifiable as we could add 10 to one of the intercepts and subtract 10 from another and get the same result). We can compare k' to the edf column to see if these numbers are close. We can also use the k-index and p-value numbers to help us too.
In this case we might think that we need to increase k, which we can try here by simply doubling it.
Note that since we only really require that k be “big enough” to model the complexity of the data, the rough doubling strategy is enough in most applications (though increasing k will always make fitting take longer).
We can note that although we increased k, we still have a relatively high EDF relative to the k we supplied. This has increased the R^2 and the deviance explained, but has it make an actual difference to our results?
Plotting
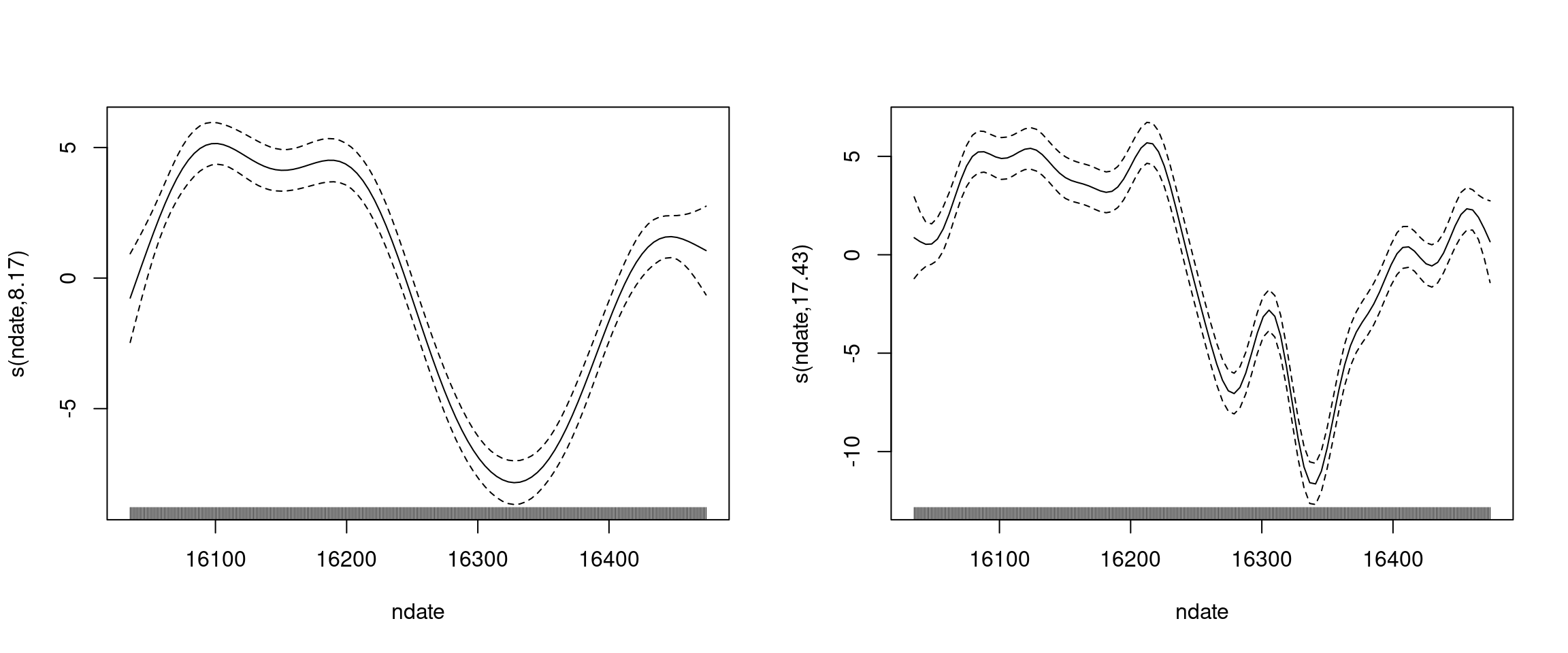
We can plot the two models to see what they look like
par(mfrow=c(1, 2))plot(b)plot(b2)
We can see that increasing k has had a dramatic effect on the resulting smooth. The general shape is the same, but there are significantly more wiggles.
Exercises
Use subset() to create a different subset of the data for a different site (you can see all site names by running unique(all_sites$SITE_NAME)) and run through the analyses above for that data.
Start by subsetting and plotting the data, how is it different to the Wytham Woods data?
Fit a simple gam() as we have above
What does that fit look like?
What do you notice in the summary()?
Is k large enough? Make some plots as you increase k