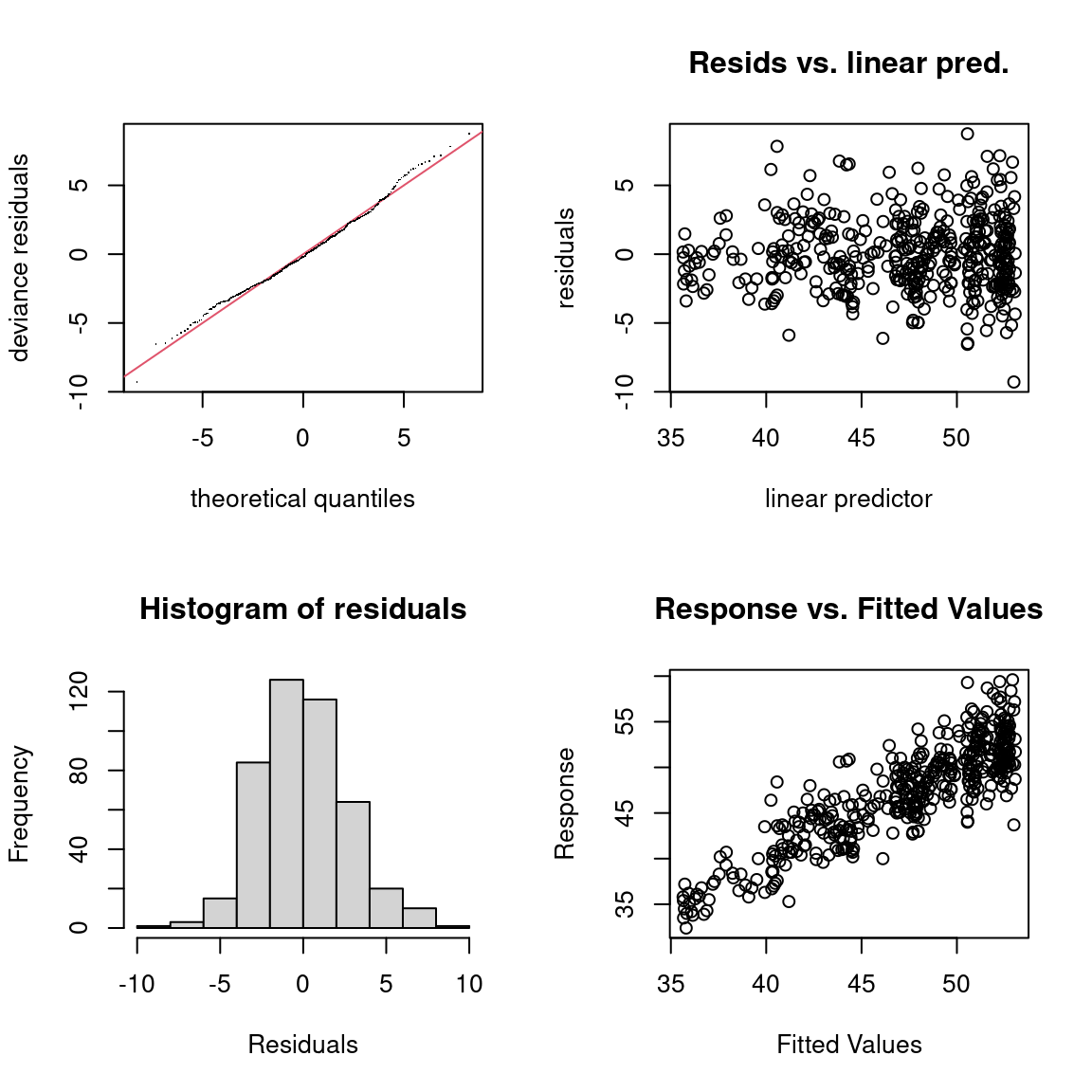
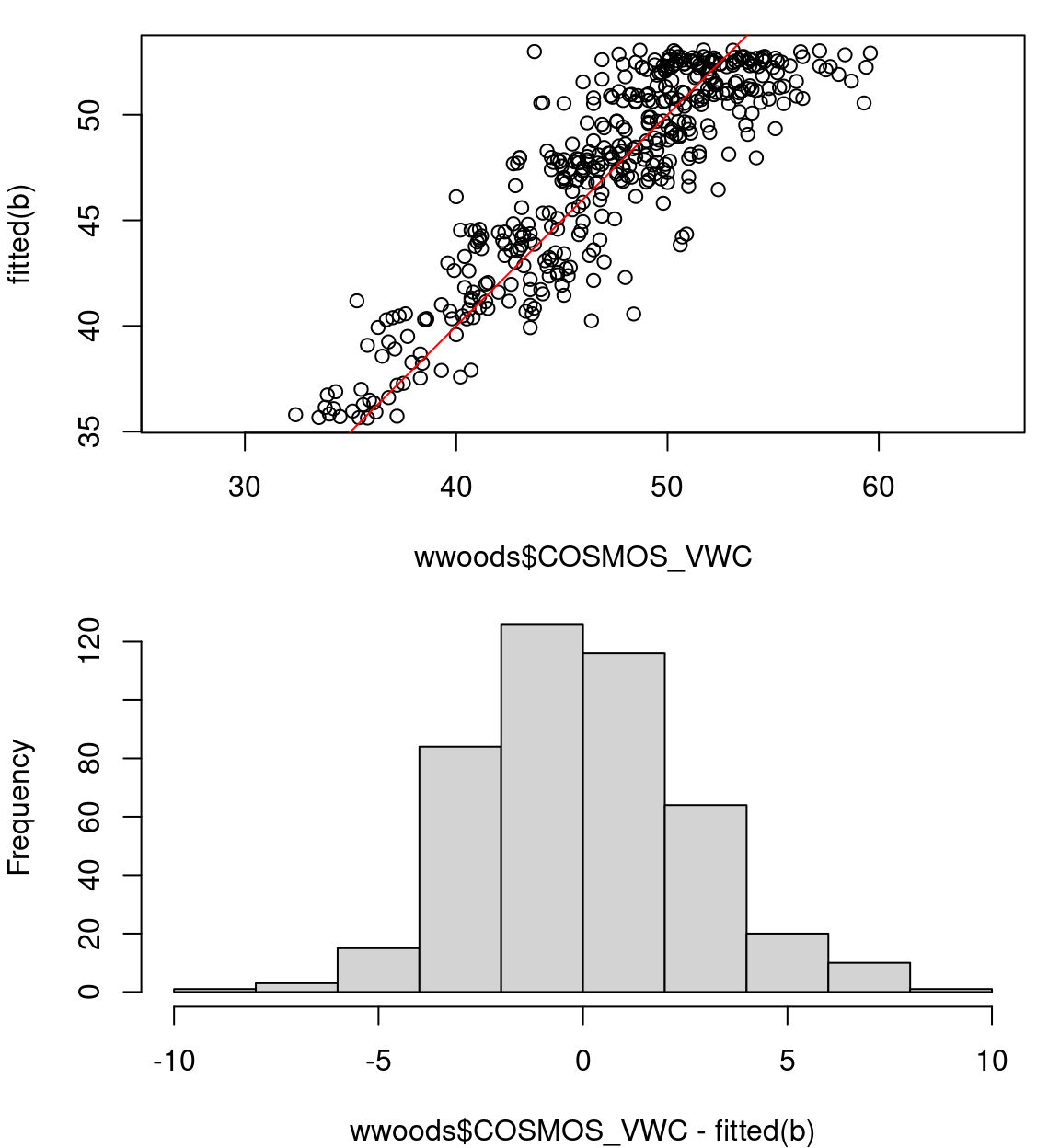
plot(b$y, fitted(b), asp=1)
abline(a=0, b=1, lwd=2, col="red")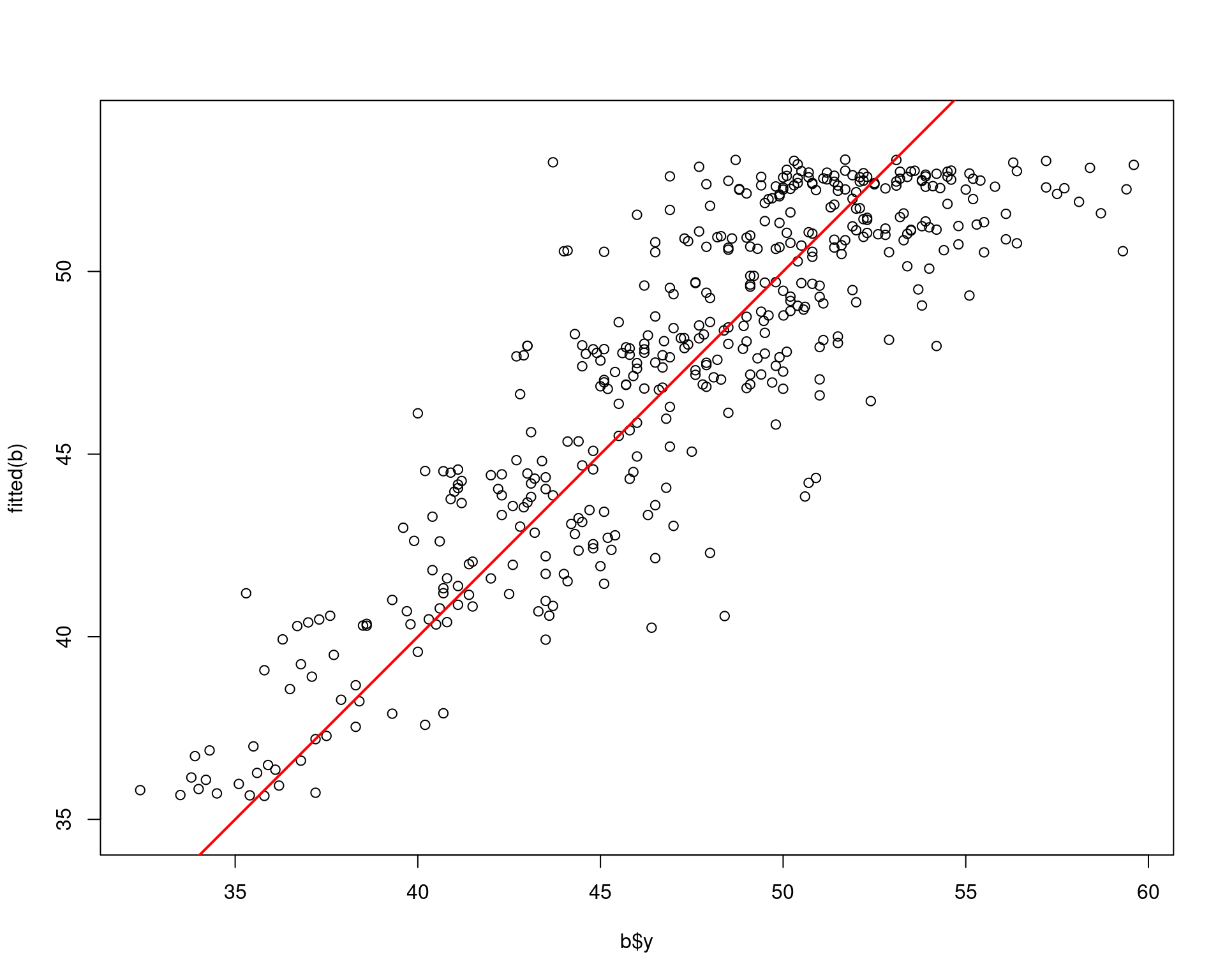
Can we just look at fitted vs. observed values?
This can be useful but there are lots of things to think about.
plot(b$y, fitted(b), asp=1)
abline(a=0, b=1, lwd=2, col="red")
qq.gam(b, asp=1, rep=200)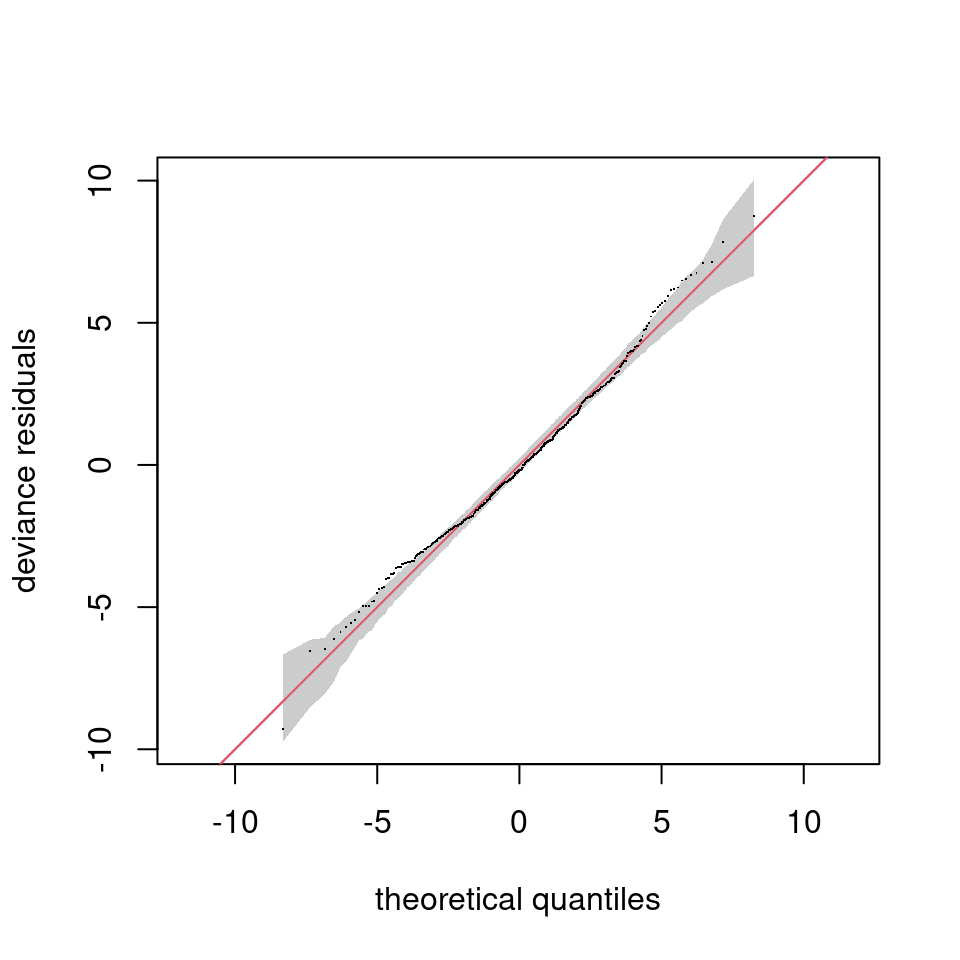
family=scat()b_t <- gam(COSMOS_VWC ~ s(ndate),
data=wwoods, method="REML",
family=scat())
qq.gam(b_t, asp=1, rep=200)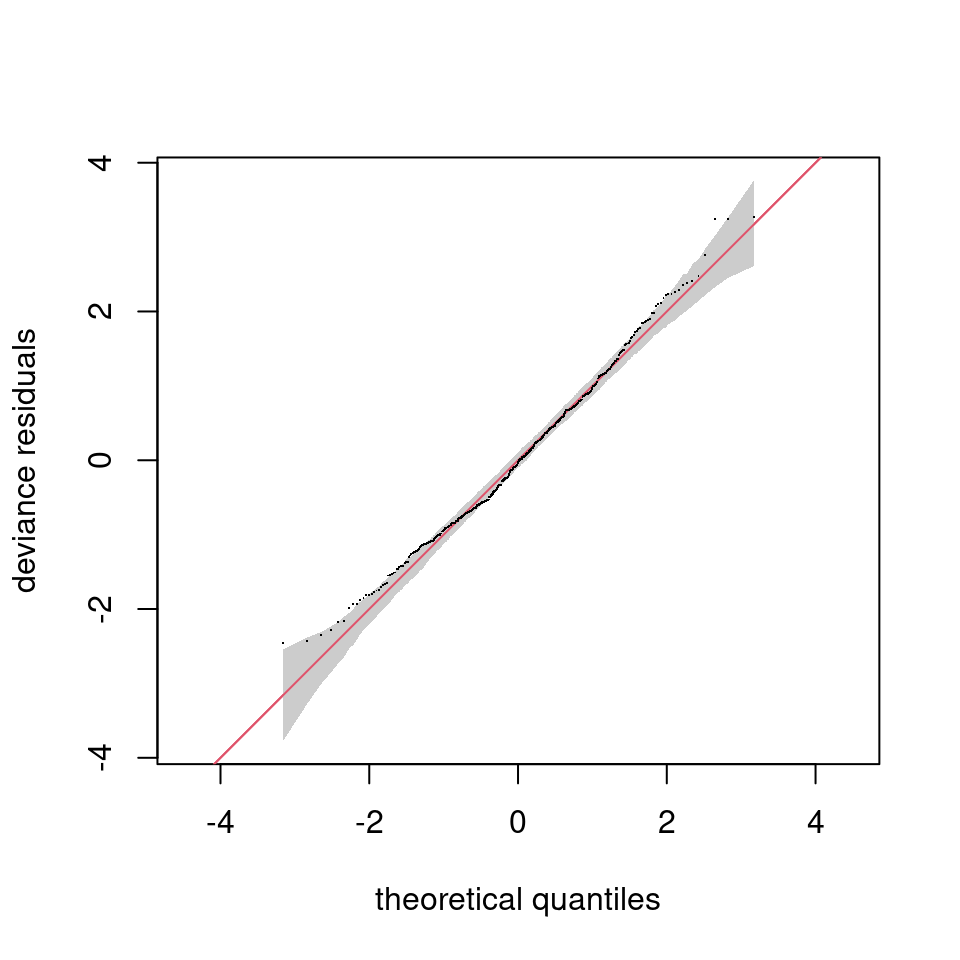
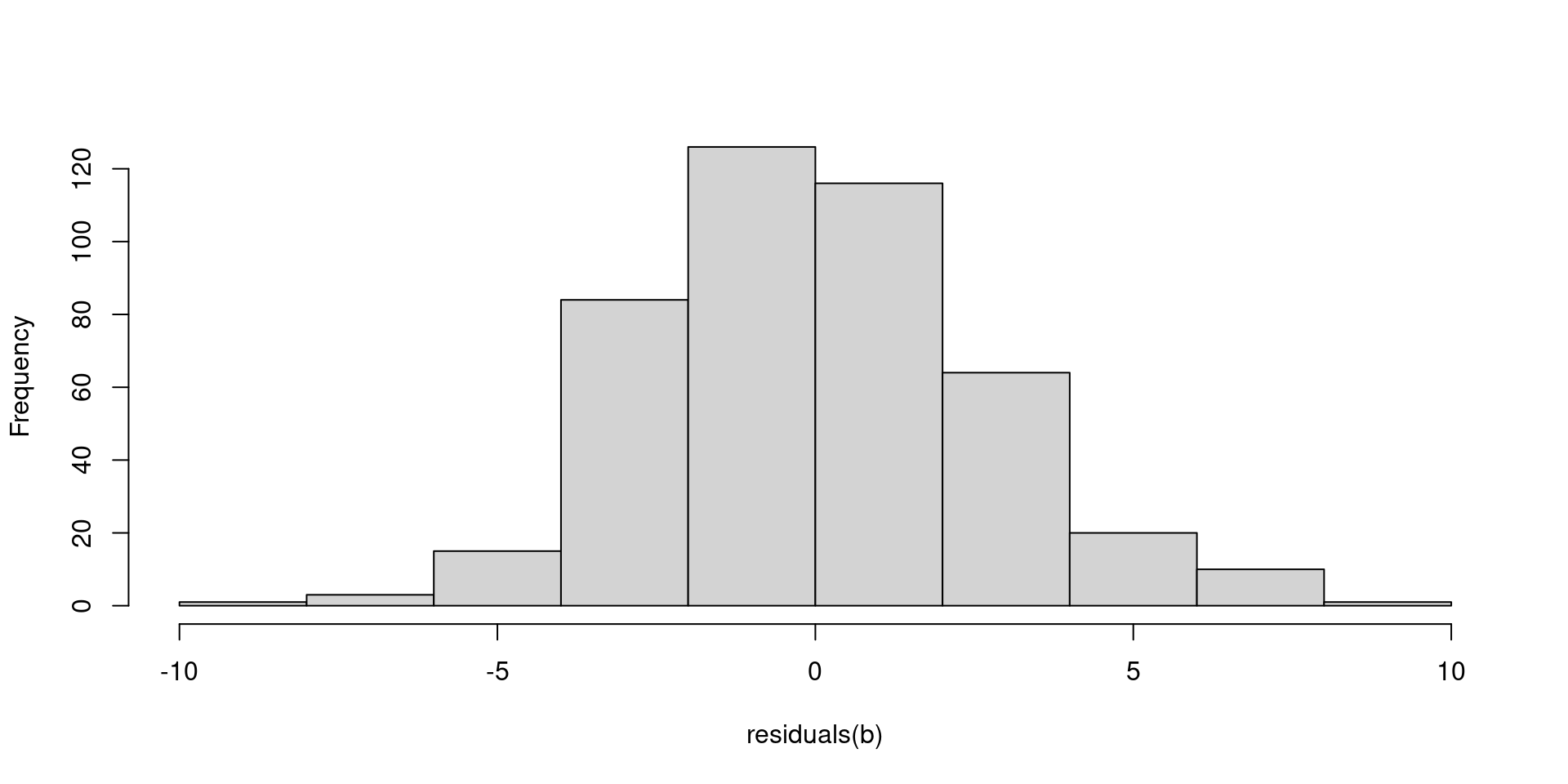
plot(fitted(b), residuals(b))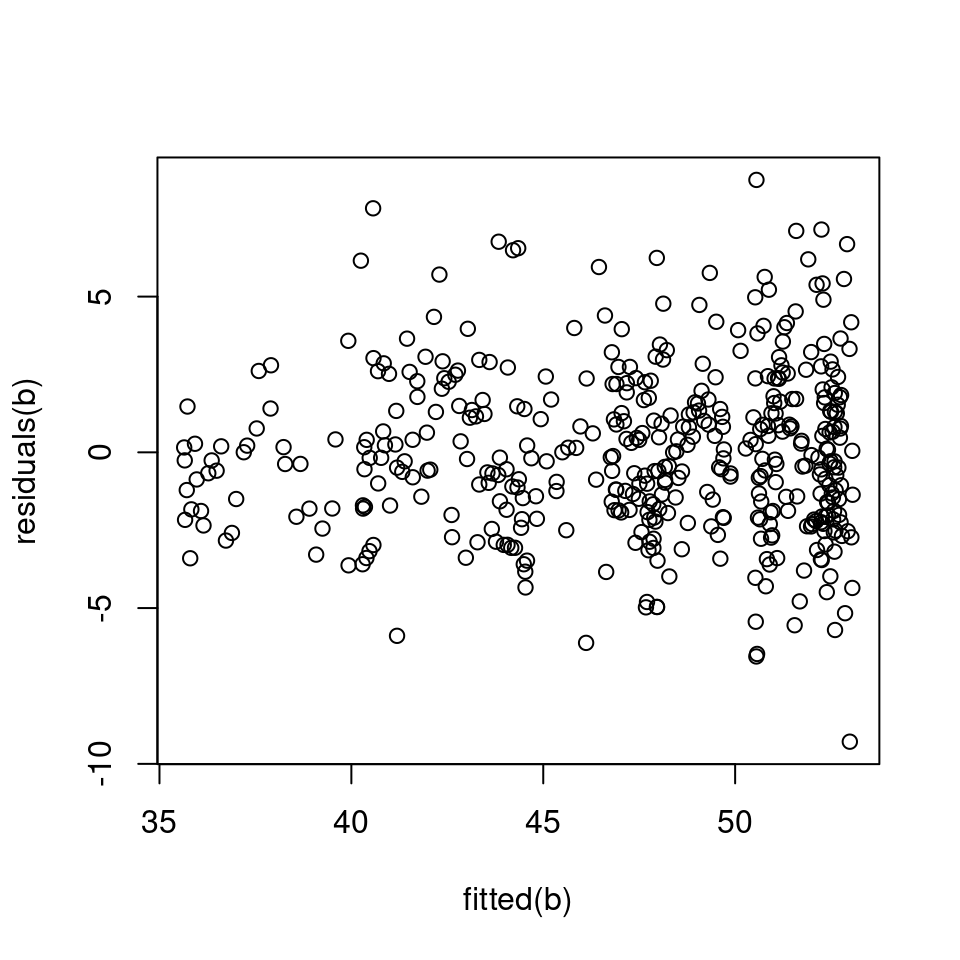
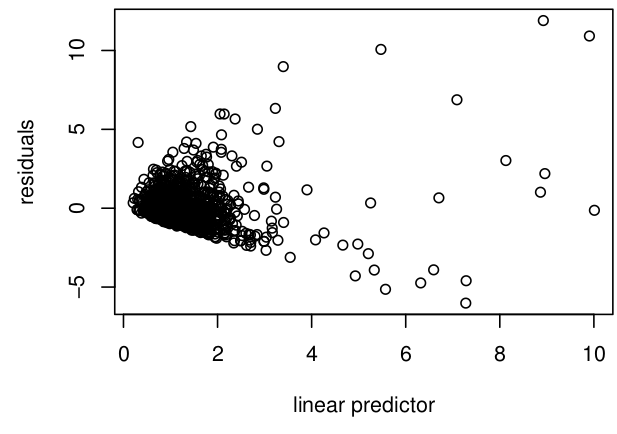
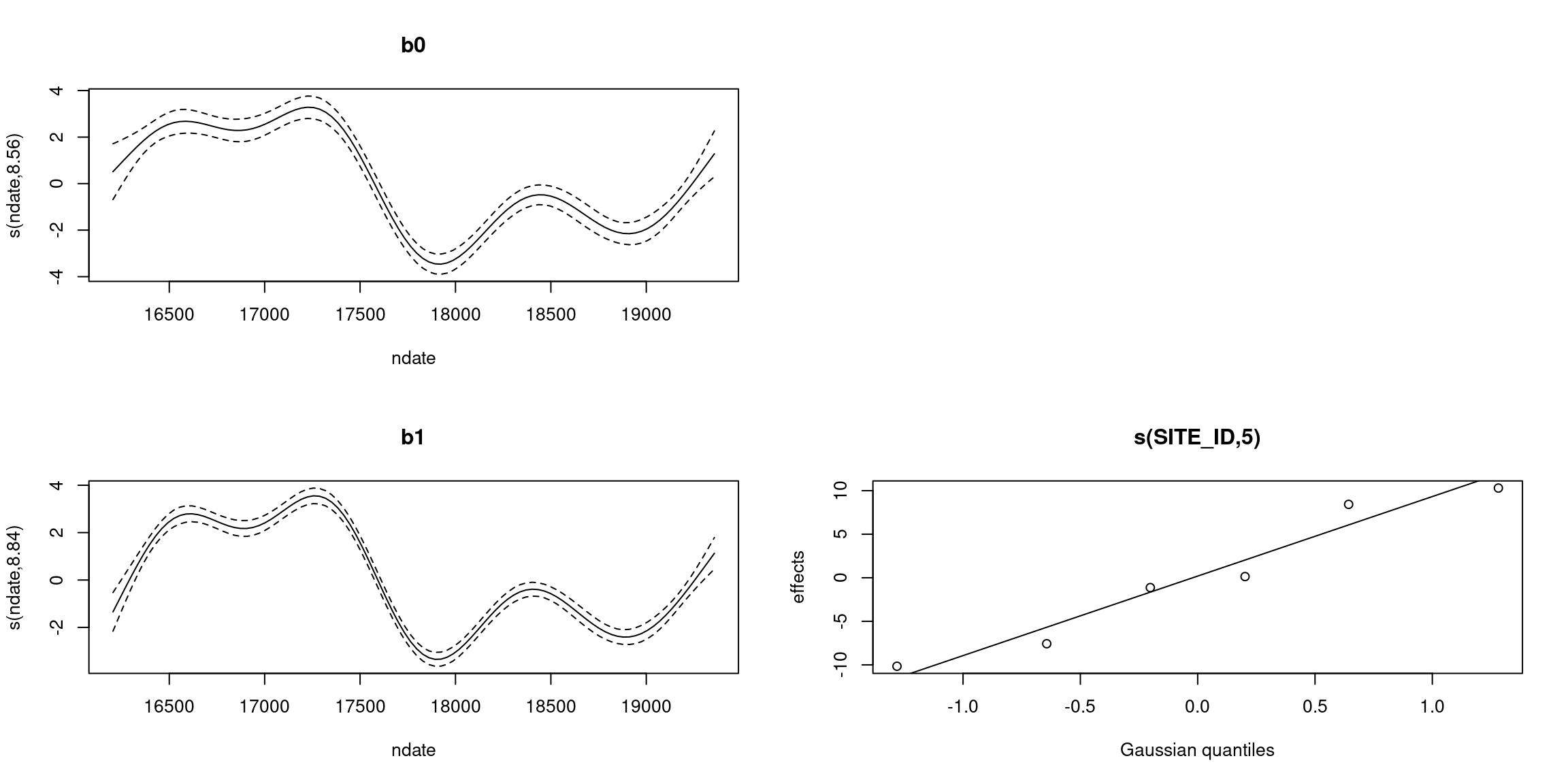
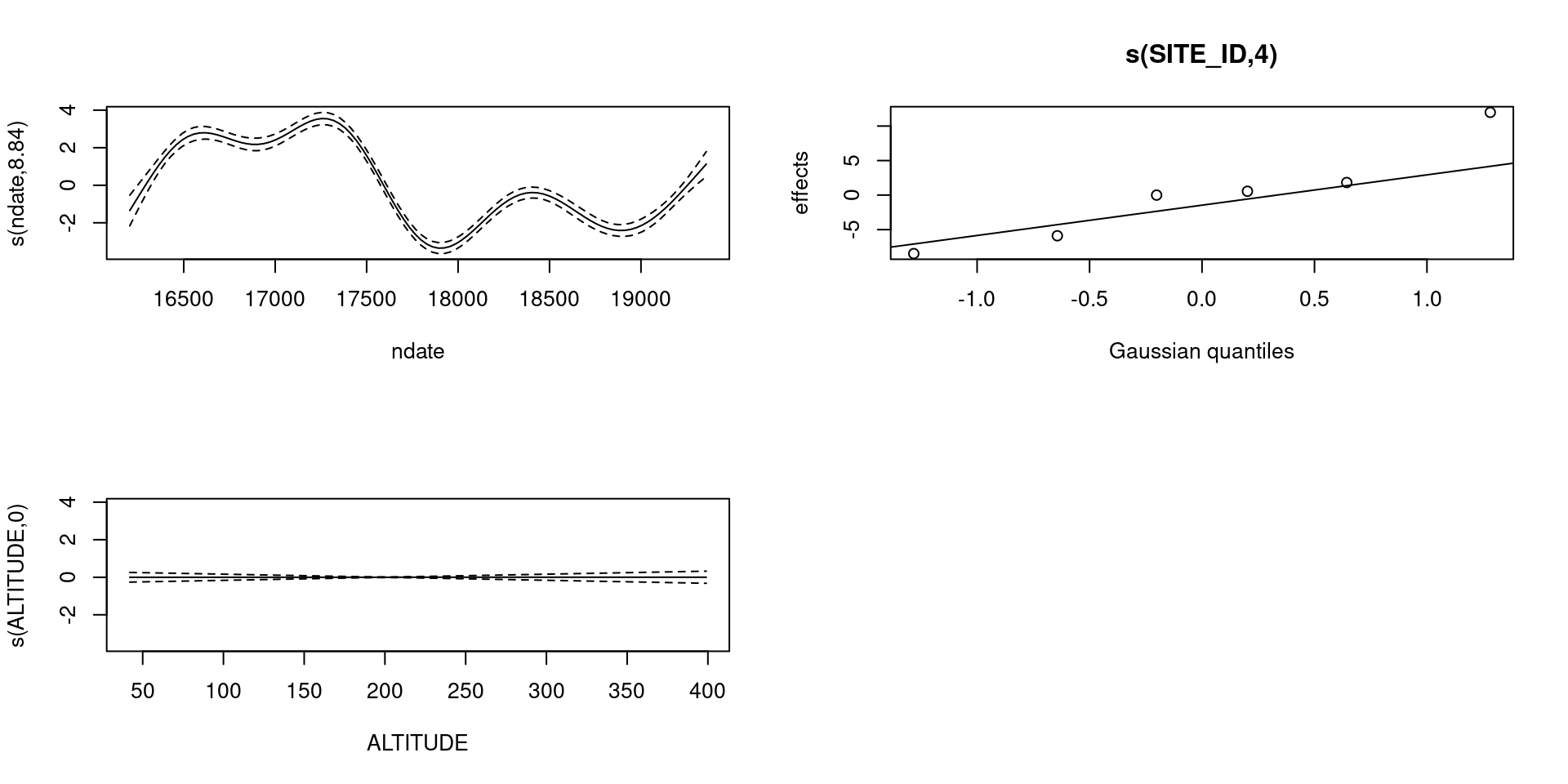
gam.check() 👌plot(b_all, pages=1)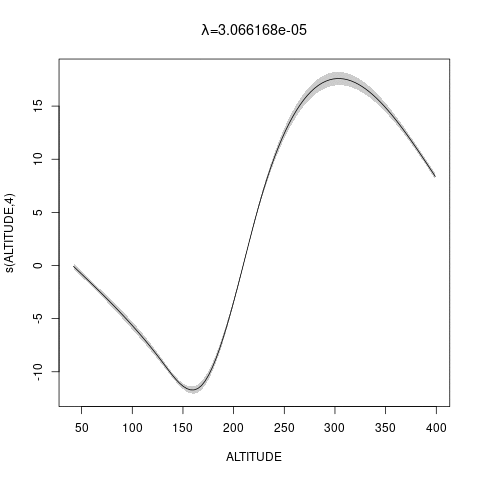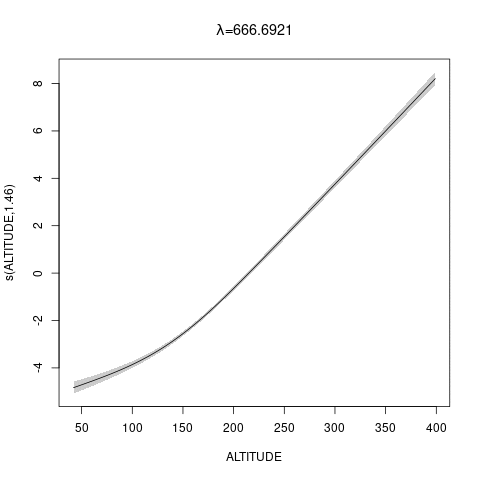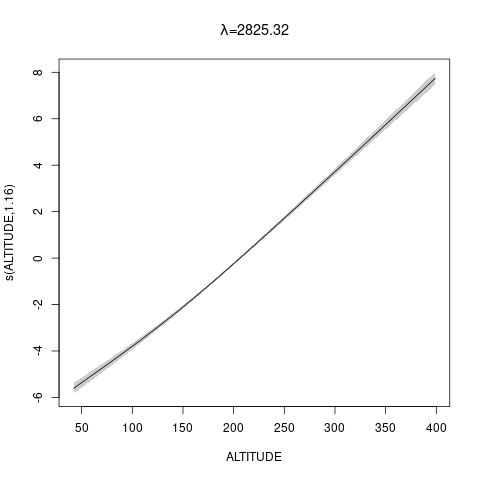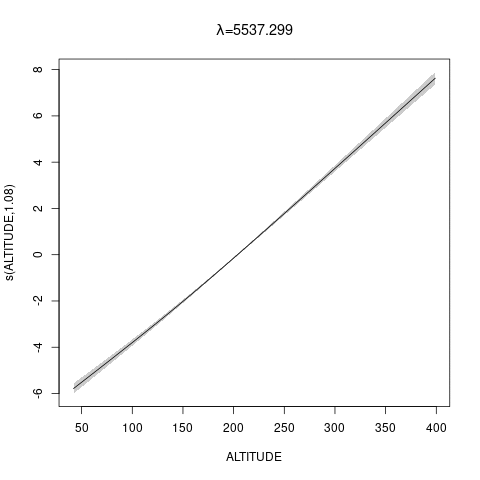
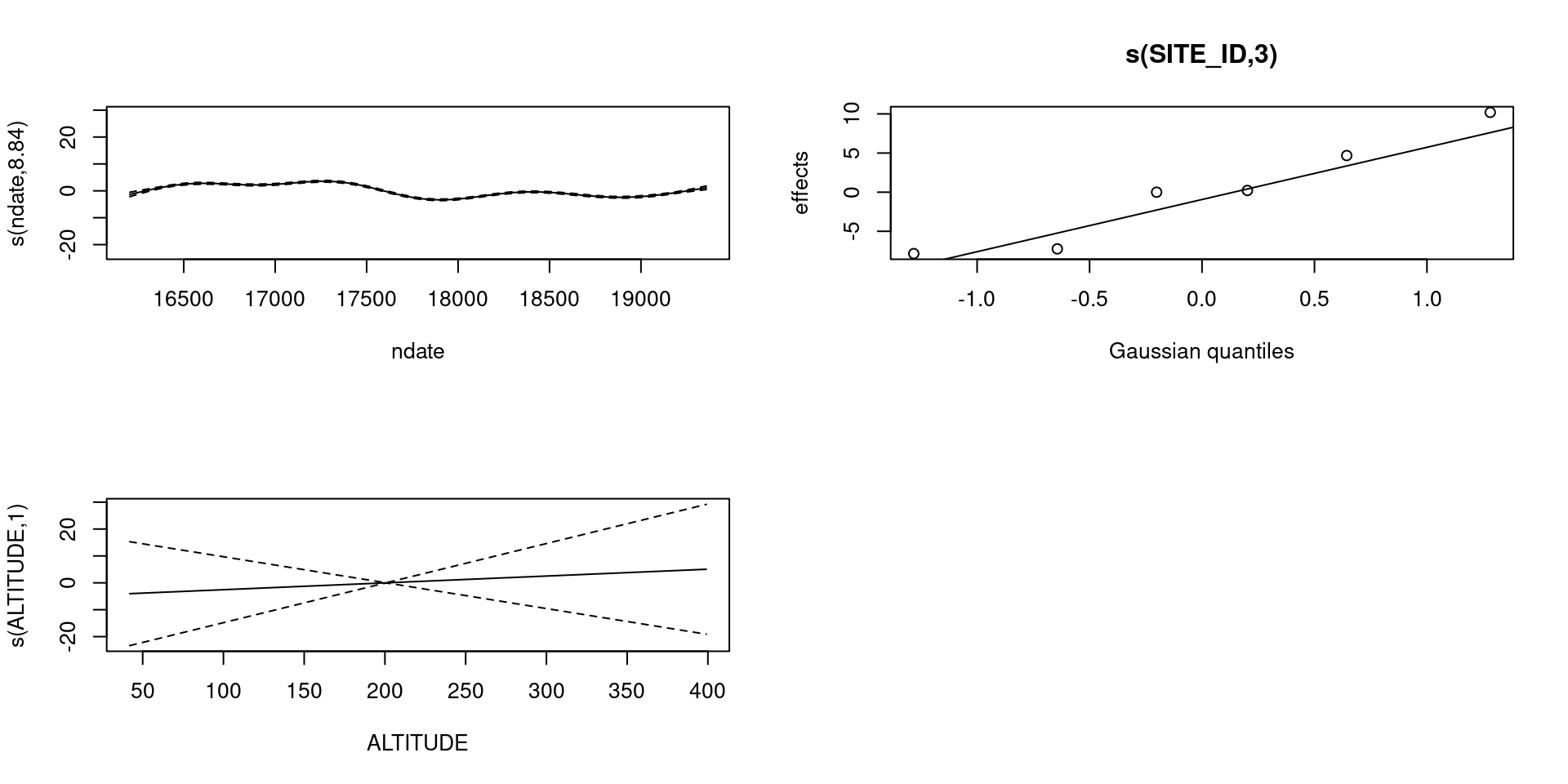
bs="ts" as we make \(\lambda\) bigger, then penalty works for nullspace terms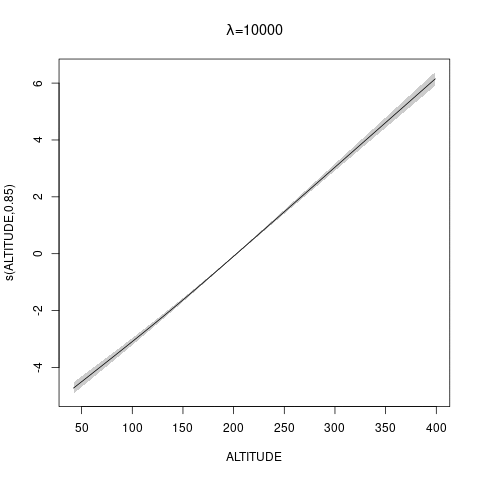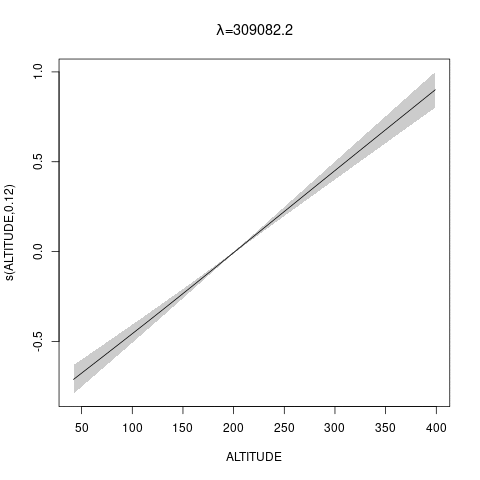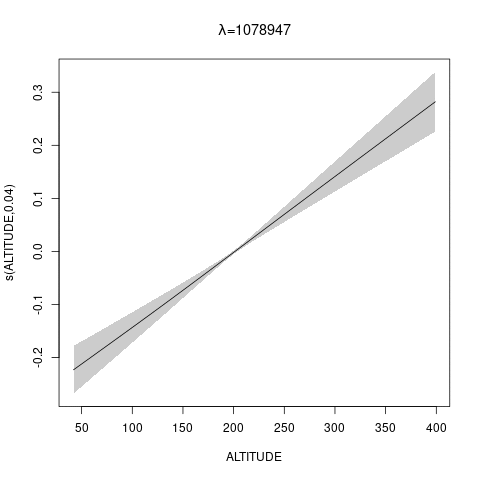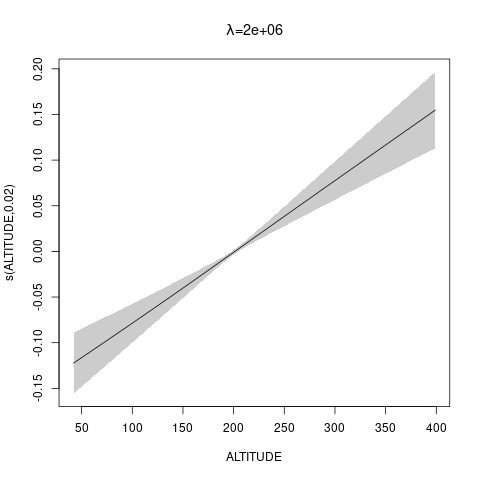
plot(b_all_ts, pages=1)