This vignette extends the models covered in vignettes 2-1 and 2-2, where the response is a function of predictor values, measured at a collection of regular distance increments in one or more dimensions, which will usually represent distance in space (spatial lags) and in time (time lags). The extension allows these functional effects to vary between groups in the data. These groups may represent any sub-population of interest, represented by factor levels in the data.
Such scenarios may arise when the dependence on environmental conditions over a neighborhood, or in the past (the “zone of influence”), differs between sub-populations in the sample.
In this vignette we’ll illustrate the theory with 1D smoothers, for notation clarity, but will illustrate the model with a 2D example in the case-study.
Mathematical description
For each observation \(i\), the linear predictor includes the additive effects of a vector predictor \(X_{i}\) consisting of values \(x_{ik}\) measured at a range of regular distances increments \(d_{ik}\) forming the distance vector \(D_i\). In typical applications, \(D_i\) is invariant between observations, so index \(i\) can be omitted. Index \(g\) encodes group membership. In typical applications, \(g\) is invariant within observations.
Function \(f_g(d_k)\) acts as a coefficient for \(x_{ik}\), that varies smoothly with distance \(d_{k}\). The shape of \(f_g(d_k)\) is typically unknown and needs to be estimated from the data, so the function should have sufficient flexibility to ensure a good fit to the data, while being sufficiently constrained to avoid overfitting. In this tutorial we will represent \(f\) with penalized regression splines, since they meet these requirements and are easily implemented using standard software.
This model is very similar to the 1D-lag model set out in vignette 2-1, but introduces two modifications:
function \(f(d_k)\) now becomes \(f_g(d_k)\). The index \(g\) represents the index of a factor level present in the data. \(f_g\) means that the shape of function \(f\) is allowed to vary across groups.
a group-level intercept \(\beta_g\) allows for differences in the mean between groups, in case the\(f_g\)functions do not include their own intercept already (we will see that in the mgcv implementation of signal regression, the intercept is included by default in the spline functions and adding it again explicitly, would lead to an unidentifiable model).
A number of alternative assumptions can be made about the structure of \(f_g\), depending on how much resemblance or difference the group-specific functions should bear between them, in a similar vein as we choose to treat factor variables either as fixed effects (no resemblance assumed) or random effects (some resemblance assumed) in conventional multilevel (= “mixed-effects”) modelling. More on this later.
R implementation
The R implementation of the model, using package mgcv, is of the form:
Where y is a dataframe column with \(N\) observations, and D, G and X are all \(N \times K\) matrices, with the number of columns \(K\) corresponding to the number of distance classes over which predictor \(X\) was measured.
Matrix D encodes the actual distances values, with equal intervals and constant across rows (if this is not the case, appropriate integration weights should be applied). The units chosen for expressing \(D\) are arbitrary and do not affect the predictions of the model (only its interpretation).
Matrix G encodes group membership (numeric or character). Group membership is row-varying and column-invariant.
The summation convention applied in mgcv means that when the data fed to the smooth terms are multi-column matrices, the sum of the function evaluation over all columns (after multiplication by the corresponding entry of any by= argument) is returned.
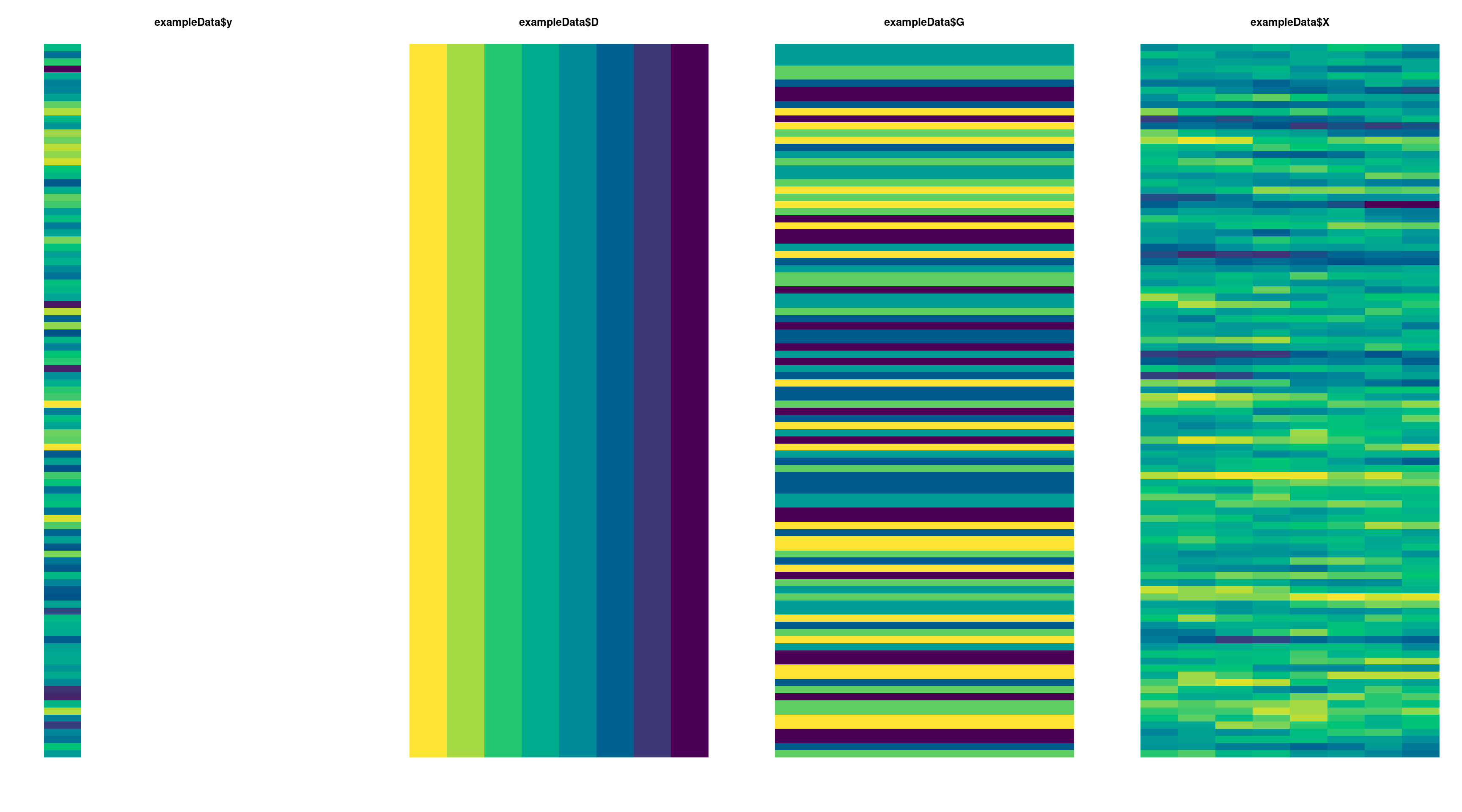
The input data should have the following structure (illustrative example with 8 distances, 100 observations and 5 groups):
y (response) is typically a single-column vector (may have two columns for binomial family or an arbitrary number for likelihoods that make use of this, such as multivariate normal).
D has one column per distance (index) value and is normally row-invariant.
G has one column per distance (index) value and is normally column-invariant.
X has same dimension as D and is NOT row-invariant. If there is correlation in the \(x_{ik}\) values between adjacent distance classes, rows of \(X\) will tend to display serial correlation patterns, as in the illustrative example above.
Illustration: analysis of kittiwake breeding success
The motivation for the model, its construction and interpretation are best shown by example. Background information about the kittiwake case study can be found in the introductory vignette (“1_Introduction”).
Specific research question #2
“How does the (spatially- and temporally-) lagged influence of SST on kittiwake yearly breeding success vary between sites (= colonies)?”
A signal regression model with spatial and temporal lags, by colony
A direct answer to the “Specific research question #2” above can be given by a signal regression using SST values at suitable spatial and temporal lags, as predictors. We additionally need to let the coefficients for SST (a function of spatial and temporal lags) vary between colonies.
A smooth component in a GAM which is allowed to vary in shape between groups of samples can be seen as a “factor-smooth interaction” and belongs to the family of multilevel (or “hierarchical”) GAMs. This can be specified in different ways depending on
whether we want to assume that all grouping levels share a common trend (group-specific functions specified as deviations from a “population-level smooth”) or have no shared trend,
whether we want to assume functions smoothness across factor levels to be identical or estimated independently.
Further guidance and code for specifying multilevel GAMs can be found in this paper: https://doi.org/10.7717/peerj.6876
Here, we will assume:
weekly SST values,
effect of SST does not extend beyond 30 weeks (~ 6 months) in the past,
effect of SST does not extend beyond 210 km from the colony, using 21 distance bands of width 10 km, centered on the colony,
lagged SST effects share a common trend and smoothness across colonies.
Data preparation
We’ll work with a larger subset of 14 colonies, kit2.
library(mgcv)
Loading required package: nlme
This is mgcv 1.9-3. For overview type 'help("mgcv-package")'.
library(ggplot2)library(patchwork)# loading the data# depending on the configuration of# your system, one of these should worktry(load("kit_SST_sandeel.RData"), silent= T)try(load("../kit_SST_sandeel.RData"), silent= T)
Modelling parameters
# number of weeks to use as predictorsnweeks<-30# distance lags (in km from colony)lags_sp<-seq(0, 210, by=10)N<-nrow(kit2)D<-length(lags_sp[-1])T<- nweeks
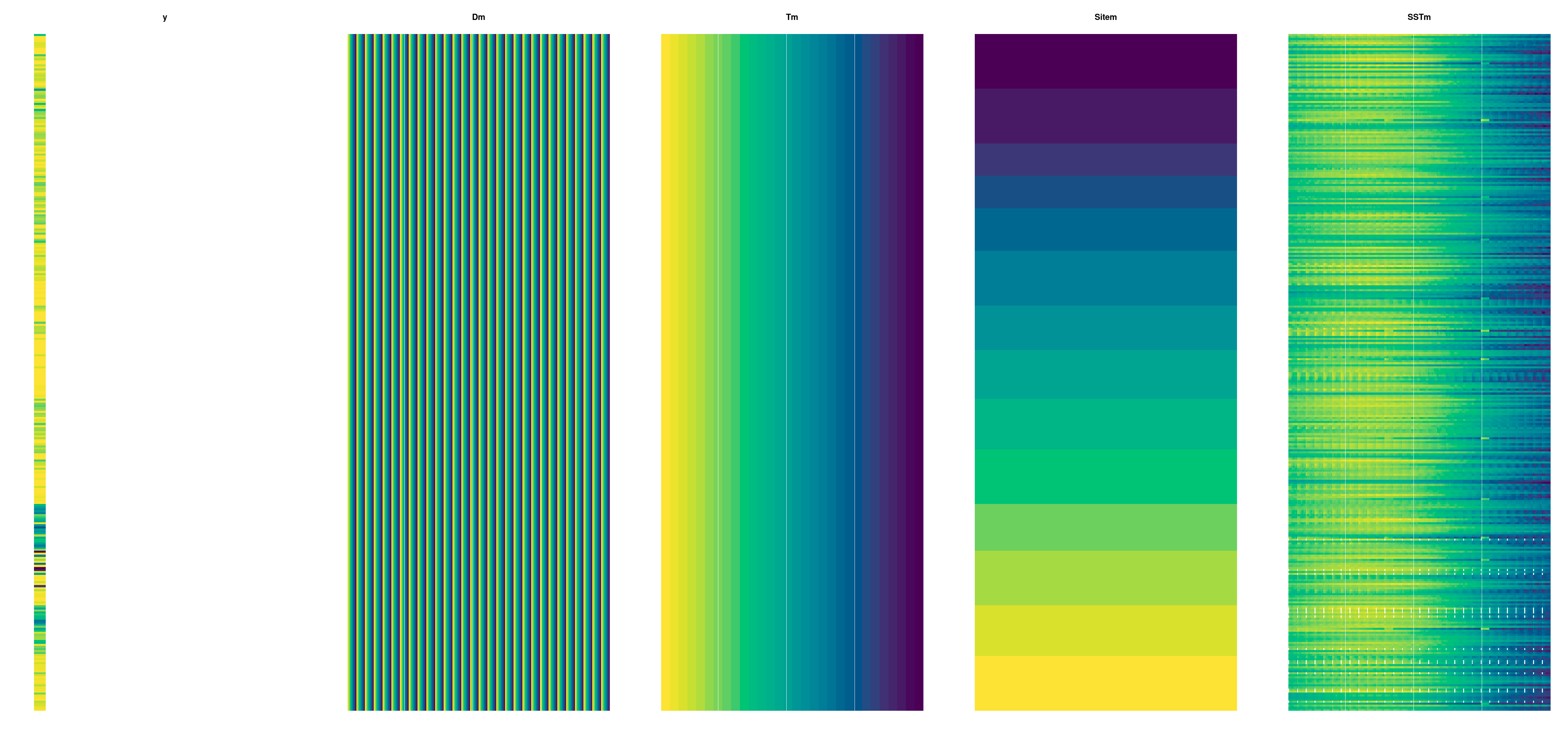
The pre-processed SST data (SST_mean_ring) come in this 3D array format:
30 rows = weekly lags
21 columns = distance bands (“spatial lags”)
334 slices = colony / year combinations
Preparing the predictor matrix thus requires unfolding the array into a matrix with adequate indices.
The following procedure works for the data format above, but will need careful adaptation for different data formats to ensure that the lag indices match across all matrices feeding into the model.
SSTm<- SST_mean_ring[, , kit2$SiteYear]dim(SSTm)<-c(D * T, N)SSTm<-t(SSTm)# visualising the first 3 rows and 8 columns of the matrix:round(SSTm, 2)[1:3, 1:8]
Now, the corresponding spatial and temporal lag indices matrices. We find convenient to annotate lags as negative week numbers, with -30 corresponding to the farthest week in time (w/c 1st Jan of that year) and -1 corresponding to the most recent. Other annotation systems can be used, without effect on the predictions of the model, as long as intervals remain all equal.
The lag combination unfolding is performed by the function expand.grid()
dt<-expand.grid(D= lags_sp[-1], T=-(nweeks:1))Dm<-matrix(dt$D, nrow=1)[rep(1, N), ]Tm<-matrix(dt$T, nrow=1)[rep(1, N), ]# Sitem<- rep(kit2$Site, times= ncol(Dm)) # incorrect coding!Sitem<-rep(kit2$Site, each=ncol(Dm))dim(Sitem)<-dim(Dm)# visualising the first 3 rows and 8 columns of the matrices:Dm[1:3, 1:8]
[,1] [,2] [,3]
[1,] Coquet Island RSPB Coquet Island RSPB Coquet Island RSPB
[2,] Coquet Island RSPB Coquet Island RSPB Coquet Island RSPB
[3,] Coquet Island RSPB Coquet Island RSPB Coquet Island RSPB
[,4] [,5] [,6]
[1,] Coquet Island RSPB Coquet Island RSPB Coquet Island RSPB
[2,] Coquet Island RSPB Coquet Island RSPB Coquet Island RSPB
[3,] Coquet Island RSPB Coquet Island RSPB Coquet Island RSPB
[,7] [,8]
[1,] Coquet Island RSPB Coquet Island RSPB
[2,] Coquet Island RSPB Coquet Island RSPB
[3,] Coquet Island RSPB Coquet Island RSPB
14 Levels: Coquet Island RSPB Dunbar Coast Fair Isle Farne Islands ... Sumburgh Head
Visual inputs check (yellow is lowest value, blue highest):
Fitting the model
An offset offset(log(AON + 1)) is used to standardise the number of chicks by the number of monitored nests (see Introduction vignette)
SST values at each of 30 time lags and 21 distance lags are contained in matrix SSTm. Their effect on kittywake breeding success across all sites (colonies) is assumed to vary smoothly with both the spatial and temporal lag (encoded in matrices Dm and Tm). This is captured by the term te(Dm, Tm, bs= c("tp", "tp"), by= SSTm), which we will call “population-level lagged effect”
The shape of the lagged SST effect is further allowed to differ between sites Sitem. This is captured by the term te(Dm, Tm, Sitem, bs= c("tp", "tp", "re"), by= SSTm), which we will call “site-level lagged effect” and measures site deviations from the population-level function.
a site fixed effect is included to account for unknown variation in the mean breeding success between colonies.
Data are assumed to follow a Tweedie distribution with a log link, which helps modelling overdispersion in the data.
Family: Tweedie(p=1.425)
Link function: log
Formula:
Fledg ~ offset(log(AON + 1)) + Year + Site + te(Dm, Tm, by = SSTm,
bs = c("tp", "tp"), k = c(4, 4)) + te(Dm, Tm, Sitem, by = SSTm,
bs = c("tp", "tp", "re"), k = c(4, 4, 14))
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.397696 13.600384 1.500 0.134739
Year -0.009486 0.006923 -1.370 0.171656
SiteDunbar Coast -0.578380 0.252541 -2.290 0.022713
SiteFair Isle -0.911856 0.275167 -3.314 0.001035
SiteFarne Islands -0.484508 0.271584 -1.784 0.075451
SiteFoula -1.092856 0.313107 -3.490 0.000556
SiteMarwick Head -0.649229 0.296374 -2.191 0.029266
SiteNoness -1.277241 0.377876 -3.380 0.000822
SiteNorth Hill RSPB, Papa Westray -0.825927 0.332362 -2.485 0.013509
SiteNorth Sutor Of Cromarty/Castlecraig -0.858081 0.317325 -2.704 0.007247
SiteRow Head -0.521021 0.308523 -1.689 0.092323
SiteSaltburn Cliffs (Huntcliff) -0.547297 0.308606 -1.773 0.077187
SiteSands of Forvie -0.782722 0.333692 -2.346 0.019657
SiteSt Abb's Head NNR -0.747811 0.290079 -2.578 0.010424
SiteSumburgh Head -1.104927 0.304626 -3.627 0.000338
(Intercept)
Year
SiteDunbar Coast *
SiteFair Isle **
SiteFarne Islands .
SiteFoula ***
SiteMarwick Head *
SiteNoness ***
SiteNorth Hill RSPB, Papa Westray *
SiteNorth Sutor Of Cromarty/Castlecraig **
SiteRow Head .
SiteSaltburn Cliffs (Huntcliff) .
SiteSands of Forvie *
SiteSt Abb's Head NNR *
SiteSumburgh Head ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Approximate significance of smooth terms:
edf Ref.df F p-value
te(Dm,Tm):SSTm 4.466 4.814 0.282 0.945109
te(Dm,Tm,Sitem):SSTm 5.688 142.000 0.135 0.000644 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
R-sq.(adj) = 0.755 Deviance explained = 19.3%
-REML = 1619.1 Scale est. = 7.8189 n = 320
The model summary suggests that there is clear variation in lagged SST effect between colonies, but it is not possible from this summary to tell which of the temporal lag, spatial lag, or site dimensions are significant sources of variation.
Plotting the estimated effects would help interpreting the results, but for this model the default function plot.gam(m_dts) doesn’t work.
We are going to have to make our own predictions and plots from the model, focussing here on the component of greatest interest to us, the spatio-temporal lag function. This function is the sum of two terms: te(Dm, Tm, by= SSTm, bs= c("tp", "tp")) and te(Dm, Tm, Sitem, by= SSTm, bs= c("tp", "tp", "re")).
This is a bit involved / tedious, but the general strategy is as follows:
create a prediction data frame for an arbitrary site including all combinations of \(D\) and \(T\) values, in long format.
assume AON value is 1 (largely irrelevant for our purpose, but effectively scales predictions to represent effect per nest)
assume SST value is 1 unit (in this way we predict the value of the SST coefficient, i.e. \(f_site(d,t)\), which is what we require for mechanistic interpretation)
make as many copies of the data as there are sites (still in long format)
assign each copy to a site
use iterms to get per-term predictions for the terms of interest to us (terms 3 and 4)
sum predictions of terms 3 and 4
plot per site
Note that this strategy is only appropriate for making term-specific predictions, for lagged components. A different approach is required to make predictions from the whole model (e.g., to predict the response), as this requires taking the sum of the contributions of all lags.
Step 1: create data set for prediction
# create a prediction data frame for an arbitrary site# including all combinations of D and T values, in long format.pdt<-data.frame(Dm= Dm[1,],Tm= Tm[1,],Sitem= Sitem[1,],Site= Sitem[1,1],SSTm=matrix(rep(1, ncol(Dm))),AON=1,Year=2005)# now make as many copies as there are sites, for making site-specific plotsour_sites<-as.character(unique(kit2$Site))pdt<- pdt[rep(1:nrow(pdt), length(our_sites)), ]pdt$Sitem<-factor(rep(our_sites, each=ncol(Dm)), levels=levels(Sitem))pdt$Site<-factor(rep(our_sites, each=ncol(Dm)), levels=levels(Sitem))
Step 2: make predictions
We need 3 levels of predictions:
pp= population level lagged-effect (term 3)
ps= site level lagged-effect deviation from population-level effect (term 4)
p= total site-level lagged effect (sum of above)
# use iterms to get per-term predictionspdt$pp<-predict(m_dts, type="iterms", newdata= pdt)[,3]pdt$ps<-predict(m_dts, type="iterms", newdata= pdt)[,4]pdt$p<- pdt$pp + pdt$ps
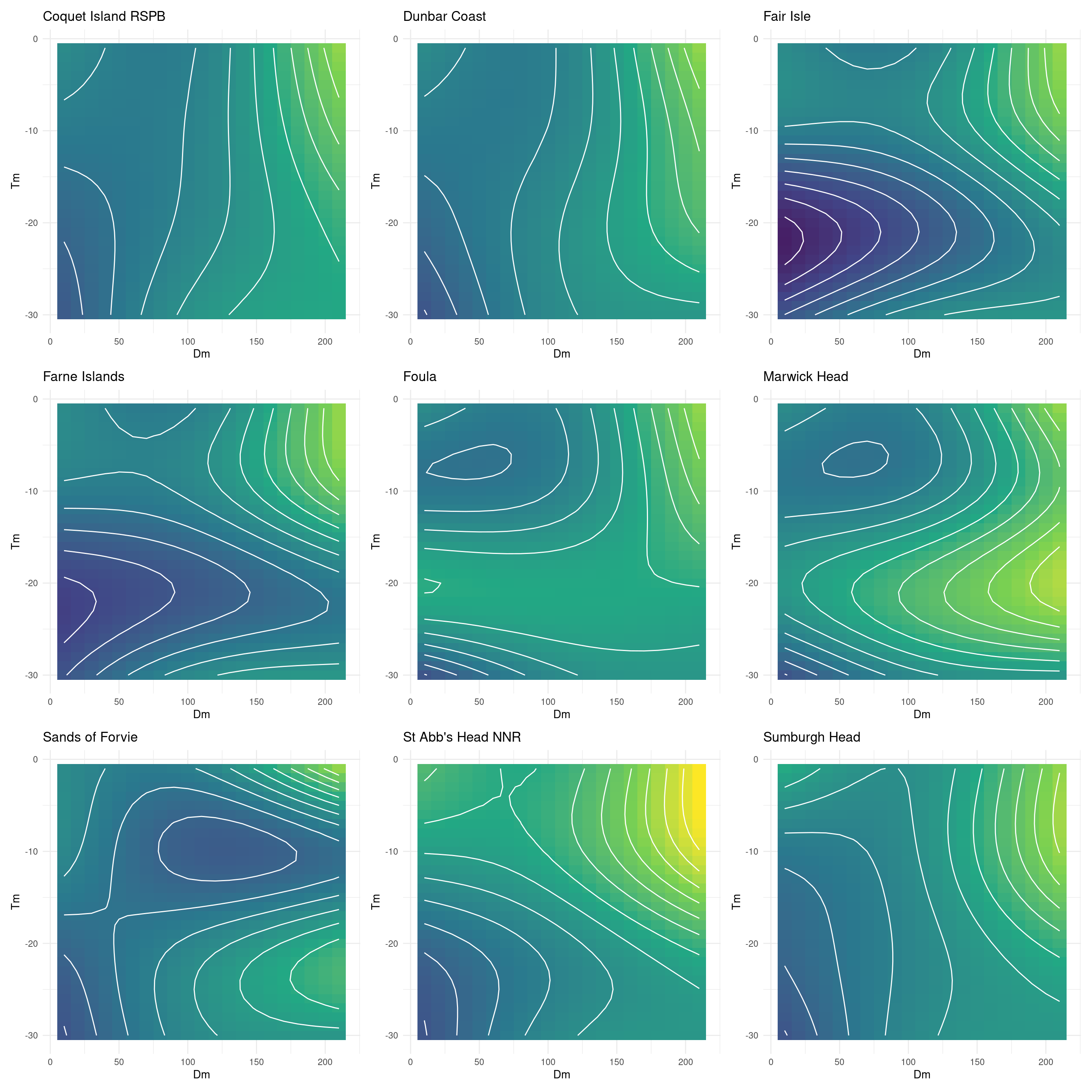
In this case the surfaces are complex and numerous enough to be tedious to interpret with this representation.
3D plotting may make the interpretation and comparison more effective, and provide
a red zero reference line, indicating no effect
custom view rotations and annotations
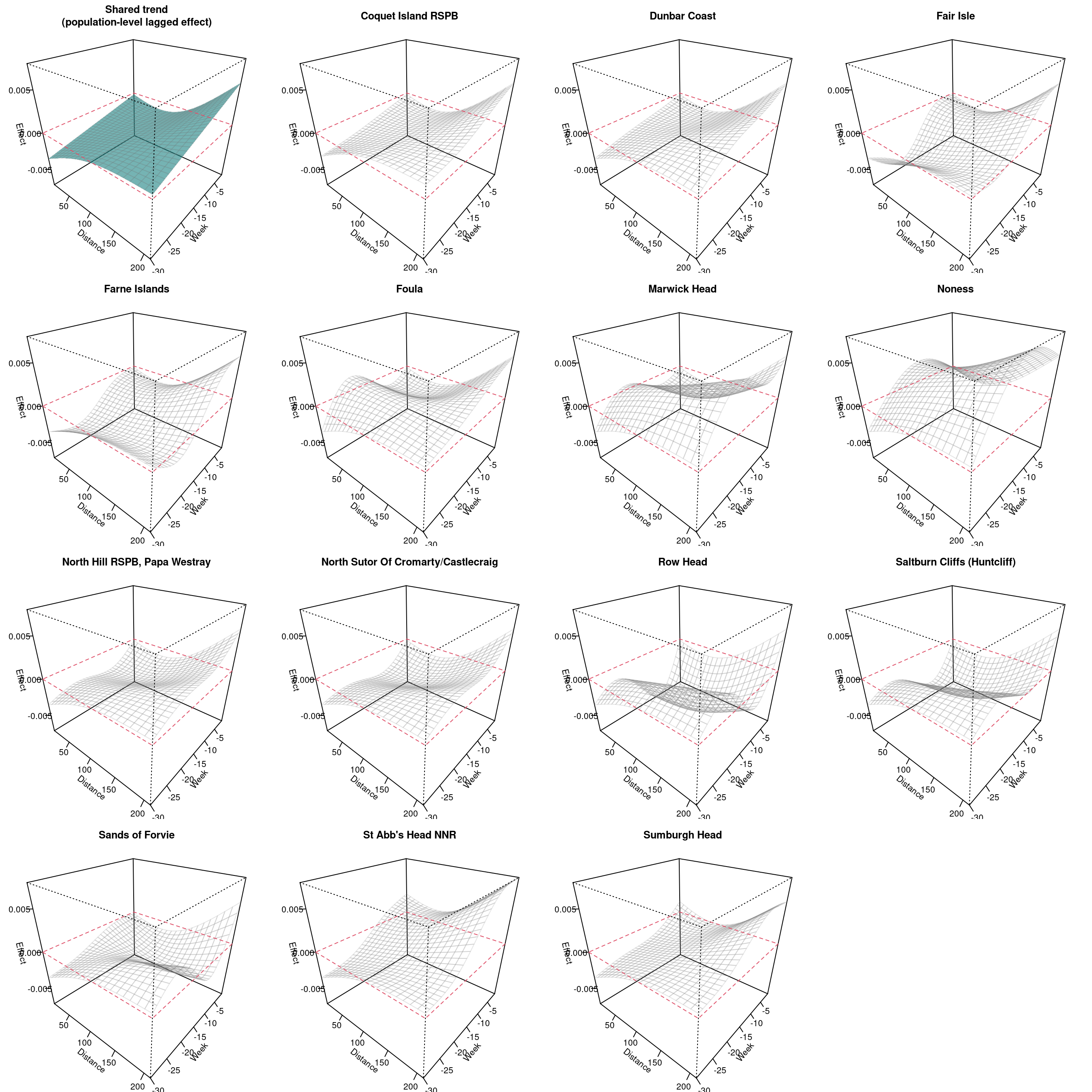
par(mfrow=c(4, 4), mar=c(0.5, 0.5, 3, 0.5))# plot population-level effectx<- our_sites[1] # choose arbitrary sitetpdt<-subset(pdt, Site==x)z_array<-array(tpdt$pp, dim=c(D, T))# plot fitted values (`p` column)persp(x= lags_sp[-1],y=-(nweeks:1),z= z_array,col=rgb(0.1, 0.5, 0.5, 0.6),border=rgb(0.5, 0.5, 0.5, 0.2),theta=40, phi=30,zlim=range(pdt$p),xlab="Distance", ylab="Week", zlab="Effect",ticktype="detailed",main="Shared trend\n(population-level lagged effect)") -> res# define x and y values for the z = 0 planex_plane<-range(lags_sp[-1])[c(1, 2, 2, 1, 1)]y_plane<-range(-(nweeks:1))[c(1, 1, 2, 2, 1)]# convert into coordinate system of perspective plotplane<-trans3d(x_plane, y_plane, 0, res)lines(plane, col =2, lwd =1, lty=2)# Plot total site-specific effects (`pp+ps`)lapply(our_sites, \(x){ tpdt<-subset(pdt, Site==x) z_array<-array(tpdt$p, dim=c(D, T))# plot fitted valuespersp(x= lags_sp[-1],y=-(nweeks:1),z= z_array,col=rgb(0.5, 0.5, 0.5, 0),border=rgb(0.5, 0.5, 0.5, 0.2),theta=40, phi=30,zlim=range(pdt$p),xlab="Distance", ylab="Week", zlab="Effect",ticktype="detailed",main= x) -> res# define x and y values for the z = 0 plane x_plane<-range(lags_sp[-1])[c(1, 2, 2, 1, 1)] y_plane<-range(-(nweeks:1))[c(1, 1, 2, 2, 1)]# convert into coordinate system of perspective plot plane<-trans3d(x_plane, y_plane, 0, res)lines(plane, col =2, lwd =1, lty=2)})
Population-level SST coefficient function (green surface): at week -30 (front), the function is negative near the colonies (left) and gradually becomes null at the extreme of the distance range. This would suggest that early in the year (week beginning 1st Jan), the effect of SST on kittiwake productivity tends to be negative near the colony, i.e. higher SST tends to correlate with lower productivity, and no effect further away. Moving towards spring and then summer, the SST effect generally becomes null (or slightly negative) near the colonies and positive beyond ~ 150 km.
Site-specific SST coefficient functions (all other panels, with transparent surfaces): the functions show are the full site-specific function, as they include both the population-level function and any site-specific deviation around it. Most sites show mostly minor deviations from the population-level pattern (qualitatively at least), but a few differ more substantially, e.g. Marwick Head, Noness, Row Head, Saltburn Cliffs, mainly over the temporal lag dimension.
It is possible to visualize only the site deviations from the population-level effect, by replacing tpdt$p by tpdt$ps in the second part of the plotting code.
Model validation
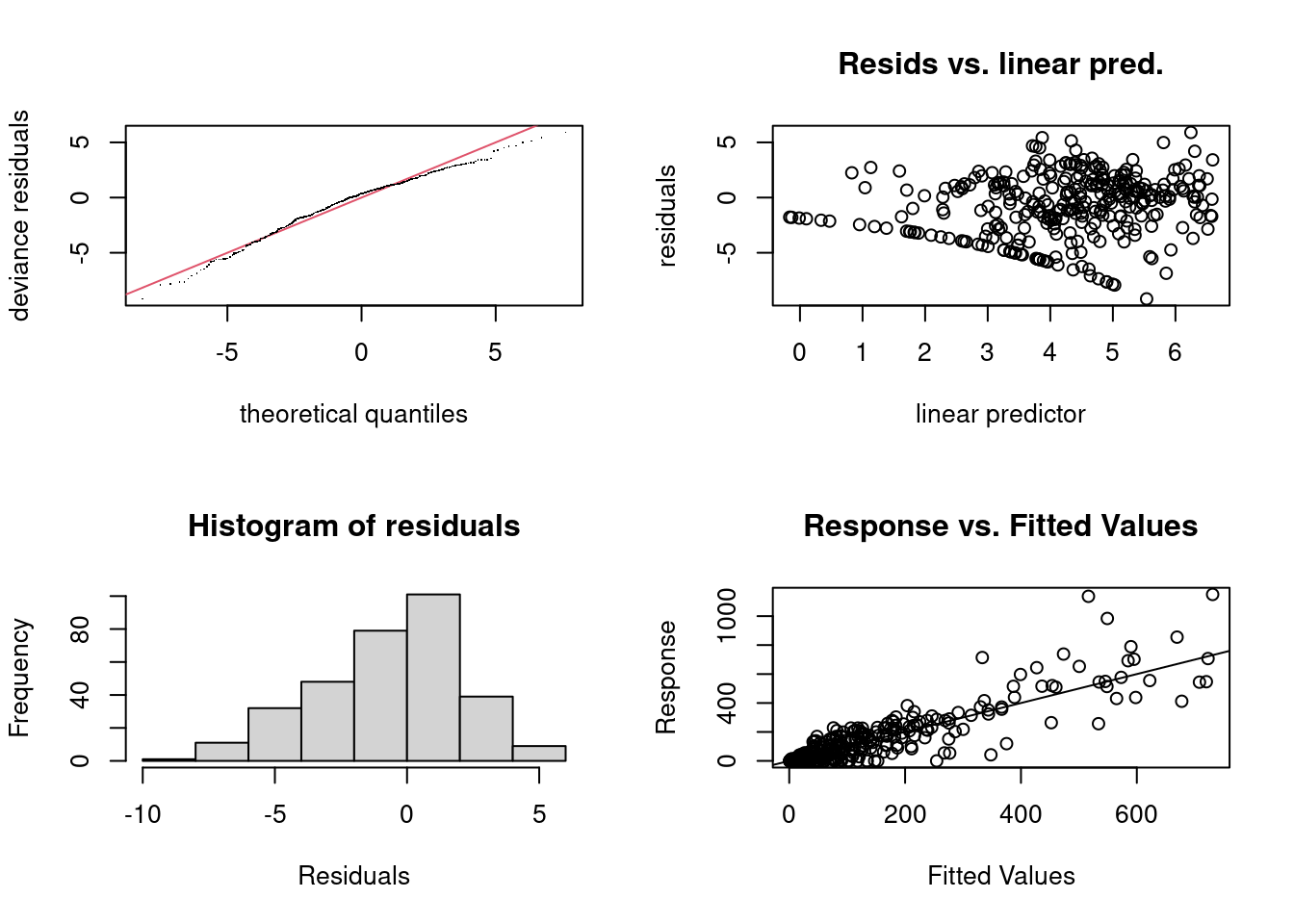
We should look at traditional GAM diagnostics, using deviance residuals.
par(mfrow=c(2, 2))gam.check(m_dts)
Method: REML Optimizer: outer newton
full convergence after 8 iterations.
Gradient range [-0.0009167038,0.0004453981]
(score 1619.08 & scale 7.818935).
Hessian positive definite, eigenvalue range [2.288871e-05,340.8777].
Model rank = 255 / 255
Basis dimension (k) checking results. Low p-value (k-index<1) may
indicate that k is too low, especially if edf is close to k'.
k' edf k-index p-value
te(Dm,Tm):SSTm 16.00 4.47 NA NA
te(Dm,Tm,Sitem):SSTm 224.00 5.69 NA NA
abline(0, 1)
These residuals diagnostics are broadly acceptable.
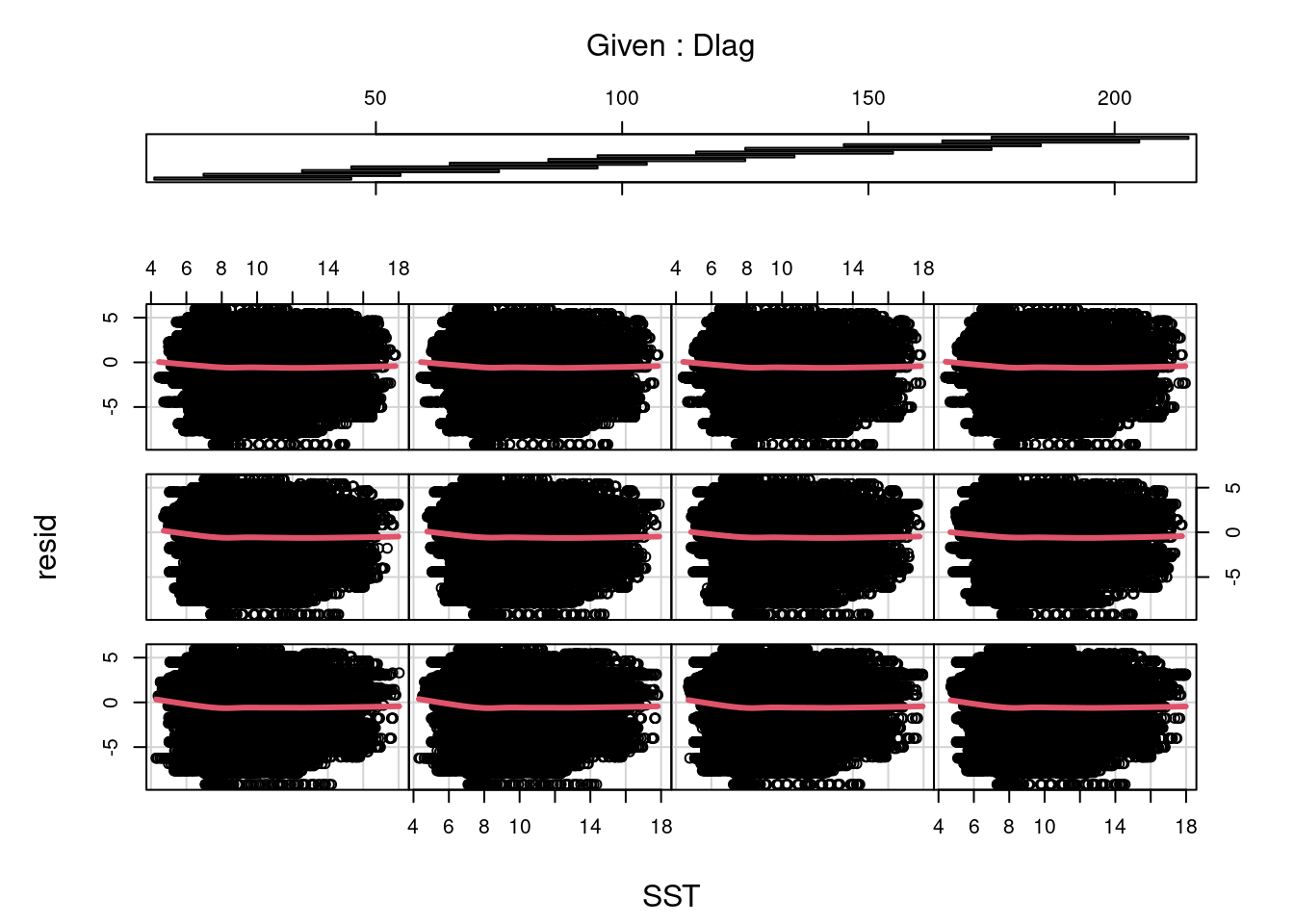
When assuming linear effects of a predictor (here, SST), it’s often worth checking for unwanted trends in the residuals against predictor values. With SST broken down into so many distinct predictors (here, 30 lags) panel plots using a sliding window of lags can an effective way of visualizing the patterns.
No apparent trend in the moving averages in red (good news).
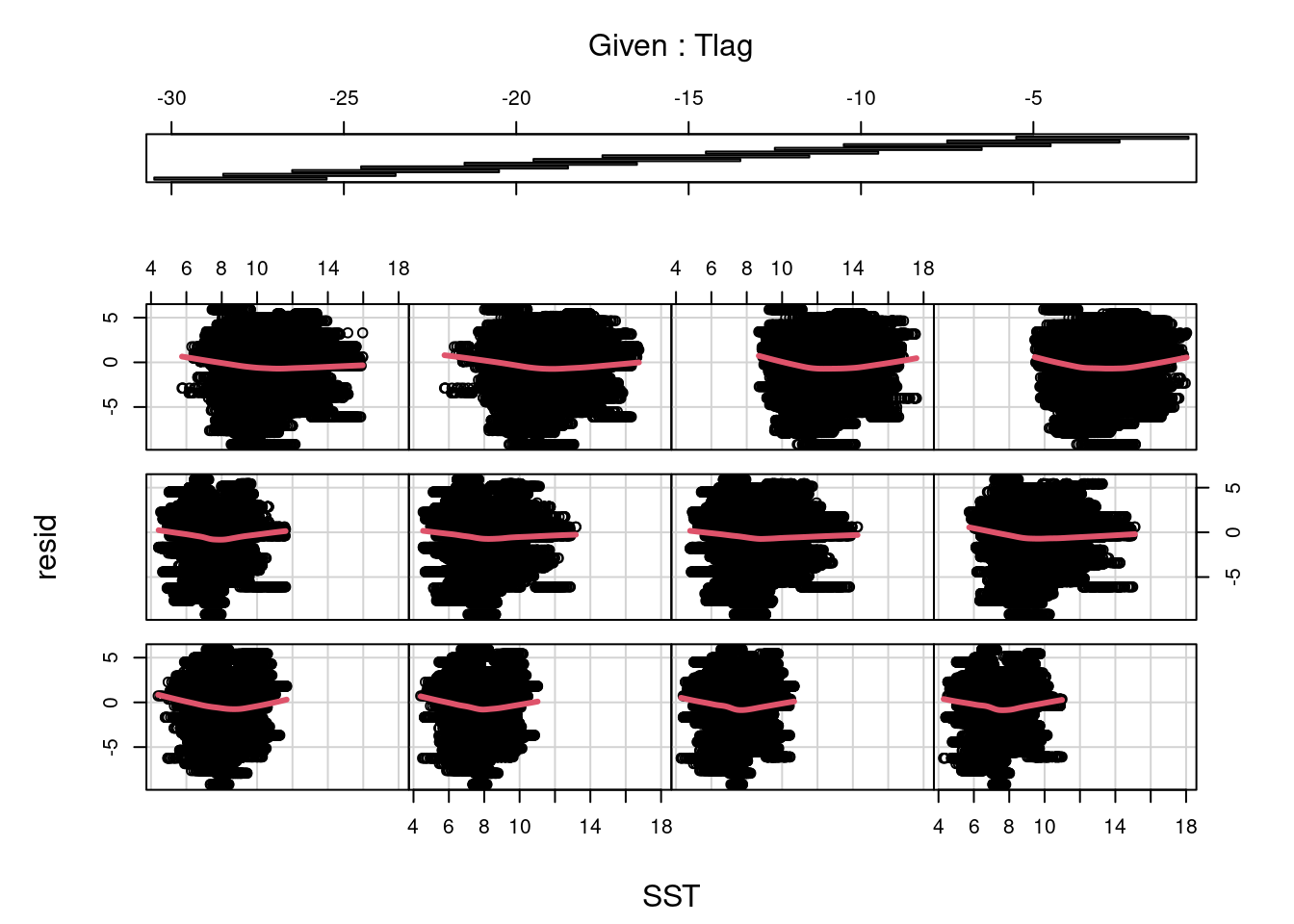
# residuals against time lagcoplot(resid ~ SST | Tlag, data= m_dts_res, panel= panel.smooth, number=12, lwd=3)
Both the mean and variance of SST increase, as we move away from winter (left to right, then bottom to top). The moving averages (red) suggest that there could be some non-linearity in the relationship with SST, which was not considered in this model.
Simulations
We will work in the 1D case for this simulation, for simplicity.
Loading a function to generate random 1D smooth functions, which will allow us to simulate the “true”/known effect (coefficient) of predictor vector \(X\) measured over a series of \(K\) lags \(D\).
lambda: a vector of length 2 specifying smoothing parameters ‘lambda’ for the 1D thin plate spline
inter: intercept value
x_l: number of x values a which to evaluate 1D smooth
require(mgcv)require(mvtnorm)
Loading required package: mvtnorm
sim_spline_1D<-function(k=7, lambda=c(0.05, 0.005), inter=0, x_l=100) {# Define the spatial domain x<-seq(0, 1, length.out= x_l) resp<-rnorm(x_l)# Open a null file connection to discard the 'jagam()' text output# Check the operating systemif (.Platform$OS.type =="unix") { null_device<-"/dev/null" } else { # Windows null_device<-"NUL" } con<-file(null_device, open="wt")# generate a template gam model object for JAGS to extract the relevant components jd<-jagam(resp ~s(x, bs="tp", k= k), file= con, diagonalize= F)close(con) S1<- jd$jags.data$S1 zero<- jd$jags.data$zero# penalty matrix K1<- S1[1:(k-1),1:(k-1)] * lambda[1] + S1[1:(k-1),k:(2*k-2)] * lambda[2]# simulate multivariate normal basis coefficients beta_sim<-c(inter, mvtnorm::rmvnorm(n=1, mean= zero[2:k], sigma= K1, method="chol"))# evaluate simulated function at x values fct_sim<- jd$jags.data$X %*% beta_simreturn(fct_sim)}# example# sim_1D<- sim_spline_1D(k= 7, lambda= c(0.05, 0.005), inter= 0, x_l= 100)# plot(sim_1D, type= "l")
Now, a function to simulate data from the model, given the known parameter values.
Output values:
X: lagged predictor matrix
Lag: lag-encoding matrix
tf: true lagged-effect function
Y: response vector
# function to simulate 1D-lagged processsim_lag_of_1D<-function(N=300, nlags=20, ngroups=10, residSD=1){# simulate time-varying predictor, where each column represents a time lag w.r.t. the observation X<-matrix(runif(N*nlags), N, nlags)# true shared coefficient function T_shared<-sim_spline_1D(x_l= nlags)# shared trend contribution to linear predictor LP_shared<- X %*% T_shared# generate ngroups in the data group<-sort(rep(1:ngroups, length.out= N)) X_group<-lapply(split(X, group), function(x) matrix(x, ncol= nlags))# true group-specific deviation from shared trend + random intercept T_group<-lapply(1:ngroups, function(x) sim_spline_1D(x_l= nlags))# standardize variances across lags T_group_sd<-apply(do.call(cbind, T_group), 1, sd) T_group<-lapply(T_group, function(x) x / T_group_sd)# apply shrinkage group_shrink<-abs(rnorm(ngroups, sd=1)) T_group<-mapply(`*`, T_group, group_shrink, SIMPLIFY= F)# group random effects group_RE<-rnorm(ngroups, sd=1)# group-specific contribution to linear predictor LP_group<-unlist(mapply(`%*%`, X_group, T_group, SIMPLIFY= F))# Linear predictor#Y<- rnorm(n= N, mean= LP_shared + # LP_group +# group_RE[group], # random group effect# sd= residSD) Y <- LP_shared + LP_group + group_RE[group] Y <- Y +rnorm(N, 0, sd=residSD) gg<-factor(paste0("G", group)) GG<-rep(gg, each= nlags)dim(GG)<-c(N, nlags)# index matrix Lag<-matrix(0:(nlags-1), N, nlags, byrow= T)list(X= X, Y= Y, ts= T_shared, tf=sapply(T_group, function(x) x + T_shared), Group= GG,group= gg,group_RE= group_RE,N= N,nlags= nlags,ngroups= ngroups,Lag= Lag)}
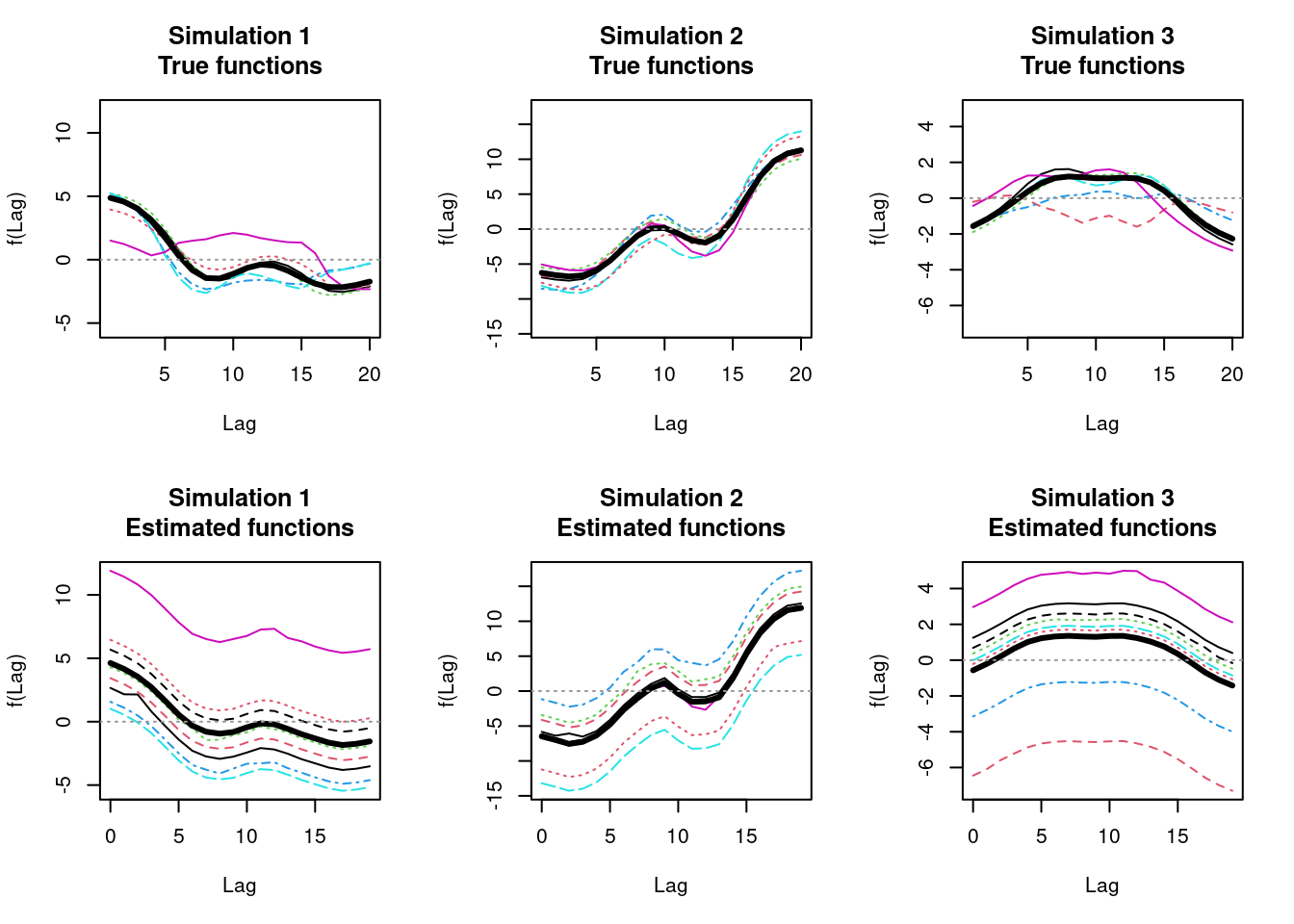
Let’s simulate 3 random data sets from 3 different sets of random model parameters, and plot the estimates of \(f(d)\) (labelled “f(Lag)”) with their 95% confidence intervals (black), together with the true values (red). The x-axis shows \(d\) (labelled “Lag”).
The shared functions are well recovered but the group-specific curves aren’t. We expect this is an error with the simulation code but haven’t yet been able to identify it.
Proposed exercises
Level 1: repeat the analysis above (spatial and temporal lags of SST).
Level 2: fit a group effect in a previous model, e.g. for lagged effects of SST (temporal or spatial only) or sandeels (spatial lags).
In all cases, pay attention to the structure of the model inputs (vectors and matrices) and take some time to reflect on the interpretation of the model outputs.
Source Code
---title: "[2-3] Block-specific lagged effects"author:- name: Thomas Cornulier thomas.cornulier@bioss.ac.uk affiliation: "Biomathematics & Statistics Scotland (https://www.bioss.ac.uk/)"- name: Dave Miller dave.miller@bioss.ac.uk affiliation: "BioSS & UKCEH"date: "Last run on `r format(Sys.time(), '%d/%m/%Y')`"output: html_document: number_sections: true self_contained: true---# The modelThis vignette extends the models covered in vignettes 2-1 and 2-2, where the response is a function of predictor values, measured at a collection of regular distance increments in one or more dimensions, which will usually represent distance in space (spatial lags) and in time (time lags). The extension allows these functional effects to vary between groups in the data. These groups may represent any sub-population of interest, represented by factor levels in the data.Such scenarios may arise when the dependence on environmental conditions over a neighborhood, or in the past (the "zone of influence"), differs between sub-populations in the sample.In this vignette we'll illustrate the theory with 1D smoothers, for notation clarity, but will illustrate the model with a 2D example in the case-study.## Mathematical descriptionFor each observation $i$, the linear predictor includes the additive effects of a vector predictor $X_{i}$ consisting of values $x_{ik}$ measured at a range of regular distances increments $d_{ik}$ forming the distance vector $D_i$. In typical applications, $D_i$ is invariant between observations, so index $i$ can be omitted. Index $g$ encodes group membership. In typical applications, $g$ is invariant *within* observations.The model is of the form:$$\mathbb{E}(y_i) = g^{-1}\left( \beta_0 + \beta_g + \sum_k f_g(d_{k}) x_{ik}\right)$$or in compact vector form,$$\mathbb{E}(y_i) = g^{-1}\left( \beta_0 + \beta_g + X_{i} f_g(D)\right)$$Function $f_g(d_k)$ acts as a coefficient for $x_{ik}$, that varies smoothly with distance $d_{k}$. The shape of $f_g(d_k)$ is typically unknown and needs to be estimated from the data, so the function should have sufficient flexibility to ensure a good fit to the data, while being sufficiently constrained to avoid overfitting. In this tutorial we will represent $f$ with penalized regression splines, since they meet these requirements and are easily implemented using standard software.This model is very similar to the 1D-lag model set out in vignette 2-1, but introduces two modifications:- function $f(d_k)$ now becomes $f_g(d_k)$. The index $g$ represents the index of a factor level present in the data. $f_g$ means that the shape of function $f$ is allowed to vary across groups.- a group-level intercept $\beta_g$ allows for differences in the mean between groups, *in case the* $f_g$ *functions do not include their own intercept already* (we will see that in the `mgcv` implementation of signal regression, the intercept is included by default in the spline functions and adding it again explicitly, would lead to an unidentifiable model).A number of alternative assumptions can be made about the structure of $f_g$, depending on how much resemblance or difference the group-specific functions should bear between them, in a similar vein as we choose to treat factor variables either as fixed effects (no resemblance assumed) or random effects (some resemblance assumed) in conventional multilevel (= "mixed-effects") modelling. More on this later.## R implementationThe R implementation of the model, using package `mgcv`, is of the form:`thisModel<- gam(y ~ te(D, G, bs= c("tp", "re"), by= X), data= exampleData)`Where `y` is a dataframe column with $N$ observations, and `D`, `G` and `X` are all $N \times K$ matrices, with the number of columns $K$ corresponding to the number of distance classes over which predictor $X$ was measured. Matrix `D` encodes the actual distances values, with equal intervals and constant across rows (if this is not the case, appropriate integration weights should be applied). The units chosen for expressing $D$ are arbitrary and do not affect the predictions of the model (only its interpretation).Matrix `G` encodes group membership (numeric or character). Group membership is row-varying and column-invariant.The summation convention applied in `mgcv` means that when the data fed to the smooth terms are multi-column matrices, the sum of the function evaluation over all columns (after multiplication by the corresponding entry of any `by=` argument) is returned.The input data should have the following structure (illustrative example with 8 distances, 100 observations and 5 groups):(here showing only the first 4 observations)```{r, echo= F}nr<-100nc<-8ng<-5set.seed(4)exampleData<-list(y=rnorm(nr, 2.5, 1),D=matrix(0:(nc-1), nr, nc, byrow= T) *5,G=sample(rep(1:ng, l= nr), nr) %*%t(rep(1, nc)),X=matrix(arima.sim(n= nr*nc, model=list(ar=0.85)), nr, nc, byrow= T))colnames(exampleData$D)<-paste0("D", 1:nc)colnames(exampleData$G)<-paste0("G_D", 1:nc)colnames(exampleData$X)<-paste0("X_D", 1:nc)exampleData<-lapply(exampleData, FUN=function(x) round(x, 2))``````{r}head(exampleData$y, n=4)head(exampleData$D, n=4)head(exampleData$G, n=4)head(exampleData$X, n=4)```Visually (yellow is lowest value, blue highest):```{r, echo= F, fig.width= 18, fig.height= 10, fig.fullwidth= T}par(mfrow=c(1, 4), bty="n", xaxt ="n", yaxt ="n")image(t(cbind(exampleData$y, matrix(NA, nr, nc-1))), col=rev(hcl.colors(64)), main="exampleData$y")image(t(exampleData$D), col=rev(hcl.colors(64)), main="exampleData$D")image(t(exampleData$G), col=rev(hcl.colors(64)), main="exampleData$G")image(t(exampleData$X), col=rev(hcl.colors(64)), main="exampleData$X")```Key features:* `y` (response) is typically a single-column vector (may have two columns for binomial family or an arbitrary number for likelihoods that make use of this, such as multivariate normal).* `D` has one column per distance (index) value and is normally row-invariant.* `G` has one column per distance (index) value and is normally column-invariant.* `X` has same dimension as `D` and is *NOT* row-invariant. If there is correlation in the $x_{ik}$ values between adjacent distance classes, rows of $X$ will tend to display serial correlation patterns, as in the illustrative example above.# Illustration: analysis of kittiwake breeding successThe motivation for the model, its construction and interpretation are best shown by example. Background information about the kittiwake case study can be found in the introductory vignette ("1_Introduction").## Specific research question #2"How does the (spatially- and temporally-) lagged influence of SST on kittiwake yearly breeding success vary between sites (= colonies)?"## A signal regression model with spatial and temporal lags, by colonyA direct answer to the "Specific research question #2" above can be given by a signal regression using SST values at suitable spatial and temporal lags, as predictors. We additionally need to let the coefficients for SST (a function of spatial and temporal lags) vary between colonies.A smooth component in a GAM which is allowed to vary in shape between groups of samples can be seen as a "factor-smooth interaction" and belongs to the family of multilevel (or "hierarchical") GAMs. This can be specified in different ways depending on 1) whether we want to assume that all grouping levels share a common trend (group-specific functions specified as deviations from a "population-level smooth") or have no shared trend,2) whether we want to assume functions smoothness across factor levels to be identical or estimated independently.Further guidance and code for specifying multilevel GAMs can be found in this paper: https://doi.org/10.7717/peerj.6876Here, we will assume:- weekly SST values,- effect of SST does not extend beyond 30 weeks (~ 6 months) in the past,- effect of SST does not extend beyond 210 km from the colony, using 21 distance bands of width 10 km, centered on the colony,- lagged SST effects share a common trend and smoothness across colonies.### Data preparationWe'll work with a larger subset of 14 colonies, `kit2`.```{r, warning= F}library(mgcv)library(ggplot2)library(patchwork)# loading the data# depending on the configuration of# your system, one of these should worktry(load("kit_SST_sandeel.RData"), silent= T)try(load("../kit_SST_sandeel.RData"), silent= T)```Modelling parameters```{r}# number of weeks to use as predictorsnweeks<-30# distance lags (in km from colony)lags_sp<-seq(0, 210, by=10)N<-nrow(kit2)D<-length(lags_sp[-1])T<- nweeks```The pre-processed SST data (`SST_mean_ring`) come in this 3D array format:* `r T` rows = weekly lags* `r D` columns = distance bands ("spatial lags")* `r N` slices = colony / year combinationsPreparing the predictor matrix thus requires unfolding the array into a matrix with adequate indices.The following procedure works for the data format above, but will need careful adaptation for different data formats to ensure that the lag indices match across all matrices feeding into the model.```{r}SSTm<- SST_mean_ring[, , kit2$SiteYear]dim(SSTm)<-c(D * T, N)SSTm<-t(SSTm)# visualising the first 3 rows and 8 columns of the matrix:round(SSTm, 2)[1:3, 1:8]```Now, the corresponding spatial and temporal lag indices matrices. We find convenient to annotate lags as negative week numbers, with -30 corresponding to the farthest week in time (w/c 1st Jan of that year) and -1 corresponding to the most recent. Other annotation systems can be used, without effect on the predictions of the model, as long as intervals remain all equal.The lag combination unfolding is performed by the function `expand.grid()````{r}dt<-expand.grid(D= lags_sp[-1], T=-(nweeks:1))Dm<-matrix(dt$D, nrow=1)[rep(1, N), ]Tm<-matrix(dt$T, nrow=1)[rep(1, N), ]# Sitem<- rep(kit2$Site, times= ncol(Dm)) # incorrect coding!Sitem<-rep(kit2$Site, each=ncol(Dm))dim(Sitem)<-dim(Dm)# visualising the first 3 rows and 8 columns of the matrices:Dm[1:3, 1:8]Tm[1:3, 1:8]Sitem[1:3, 1:8]```Visual inputs check (yellow is lowest value, blue highest):```{r, echo= F, fig.width= 25, fig.height= 12}par(mfrow=c(1, 5), bty="n", xaxt ="n", yaxt ="n")image(t(cbind(kit2$Fledg, matrix(NA, N, D))), col=rev(hcl.colors(64)), main="y")image(t(Dm), col=rev(hcl.colors(64)), main="Dm")image(t(Tm), col=rev(hcl.colors(64)), main="Tm")image(t(as.numeric(Sitem)), col=rev(hcl.colors(64)), main="Sitem")image(t(SSTm), col=rev(hcl.colors(64)), main="SSTm")```### Fitting the model* An offset `offset(log(AON + 1))` is used to standardise the number of chicks by the number of monitored nests (see Introduction vignette)* SST values at each of 30 time lags and 21 distance lags are contained in matrix `SSTm`. Their effect on kittywake breeding success across all sites (colonies) is assumed to vary smoothly with both the spatial and temporal lag (encoded in matrices `Dm` and `Tm`). This is captured by the term `te(Dm, Tm, bs= c("tp", "tp"), by= SSTm)`, which we will call "population-level lagged effect"* The shape of the lagged SST effect is further allowed to differ between sites `Sitem`. This is captured by the term `te(Dm, Tm, Sitem, bs= c("tp", "tp", "re"), by= SSTm)`, which we will call "site-level lagged effect" and measures site *deviations* from the population-level function.* a site fixed effect is included to account for unknown variation in the mean breeding success between colonies.* Data are assumed to follow a Tweedie distribution with a log link, which helps modelling overdispersion in the data.```{r}library(mgcv)m_dts<-gam(Fledg ~offset(log(AON +1)) + Year + Site +te(Dm, Tm, by= SSTm, bs=c("tp", "tp"), k=c(4,4)) +te(Dm, Tm, Sitem, by= SSTm, bs=c("tp", "tp", "re"), k=c(4,4,14)),data= kit2,family=tw(), method="REML")```### Model output & interpretation```{r}summary(m_dts)```> The model summary suggests that there is clear variation in lagged SST effect between colonies, but it is not possible from this summary to tell which of the temporal lag, spatial lag, or site dimensions are significant sources of variation.Plotting the estimated effects would help interpreting the results, but for this model the default function `plot.gam(m_dts)` doesn't work.We are going to have to make our own predictions and plots from the model, focussing here on the component of greatest interest to us, the spatio-temporal lag function. This function is the sum of two terms: `te(Dm, Tm, by= SSTm, bs= c("tp", "tp"))` and `te(Dm, Tm, Sitem, by= SSTm, bs= c("tp", "tp", "re"))`.This is a bit involved / tedious, but the general strategy is as follows:- create a prediction data frame for an arbitrary site including all combinations of $D$ and $T$ values, in long format. - assume AON value is 1 (largely irrelevant for our purpose, but effectively scales predictions to represent effect per nest) - assume SST value is 1 unit (in this way we predict the value of the SST coefficient, i.e. $f_site(d,t)$, which is what we require for mechanistic interpretation)- make as many copies of the data as there are sites (still in long format)- assign each copy to a site- use `iterms` to get per-term predictions for the terms of interest to us (terms 3 and 4)- sum predictions of terms 3 and 4- plot per siteNote that this strategy is only appropriate for making term-specific predictions, for lagged components. A different approach is required to make predictions from the whole model (e.g., to predict the response), as this requires taking the sum of the contributions of all lags.#### Step 1: create data set for prediction ```{r}# create a prediction data frame for an arbitrary site# including all combinations of D and T values, in long format.pdt<-data.frame(Dm= Dm[1,],Tm= Tm[1,],Sitem= Sitem[1,],Site= Sitem[1,1],SSTm=matrix(rep(1, ncol(Dm))),AON=1,Year=2005)# now make as many copies as there are sites, for making site-specific plotsour_sites<-as.character(unique(kit2$Site))pdt<- pdt[rep(1:nrow(pdt), length(our_sites)), ]pdt$Sitem<-factor(rep(our_sites, each=ncol(Dm)), levels=levels(Sitem))pdt$Site<-factor(rep(our_sites, each=ncol(Dm)), levels=levels(Sitem))```#### Step 2: make predictions We need 3 levels of predictions:- `pp`= population level lagged-effect (term 3)- `ps`= site level lagged-effect deviation from population-level effect (term 4)- `p`= total site-level lagged effect (sum of above)```{r}# use iterms to get per-term predictionspdt$pp<-predict(m_dts, type="iterms", newdata= pdt)[,3]pdt$ps<-predict(m_dts, type="iterms", newdata= pdt)[,4]pdt$p<- pdt$pp + pdt$ps```#### Step 3: plot per siteA `ggplot2` heatmap version:```{r, fig.fullwidth= T, fig.width= 15, fig.height= 15}# quick plotrange_max<-max(tapply(pdt$p, pdt$Site, sd)*3)pp<-lapply(our_sites, \(x){ tpdt<-subset(pdt, Site==x)ggplot(tpdt) +geom_tile(aes(x=Dm, y=Tm, fill=p)) +geom_contour(aes(x=Dm, y=Tm, z=p), col="white", binwidth= range_max /10) +scale_fill_viridis_c(guide="none", limits =c(min(pdt$p), max(pdt$p))) +ggtitle(x) +theme_minimal()})(pp[[1]] + pp[[2]] + pp[[3]]) /(pp[[4]] + pp[[5]] + pp[[6]]) /(pp[[12]] + pp[[13]] + pp[[14]])```> In this case the surfaces are complex and numerous enough to be tedious to interpret with this representation. 3D plotting may make the interpretation and comparison more effective, and provide* a red zero reference line, indicating no effect* custom view rotations and annotations```{r, fig.fullwidth= T, fig.width= 14, fig.height= 14, results= "hide"}par(mfrow=c(4, 4), mar=c(0.5, 0.5, 3, 0.5))# plot population-level effectx<- our_sites[1] # choose arbitrary sitetpdt<-subset(pdt, Site==x)z_array<-array(tpdt$pp, dim=c(D, T))# plot fitted values (`p` column)persp(x= lags_sp[-1],y=-(nweeks:1),z= z_array,col=rgb(0.1, 0.5, 0.5, 0.6),border=rgb(0.5, 0.5, 0.5, 0.2),theta=40, phi=30,zlim=range(pdt$p),xlab="Distance", ylab="Week", zlab="Effect",ticktype="detailed",main="Shared trend\n(population-level lagged effect)") -> res# define x and y values for the z = 0 planex_plane<-range(lags_sp[-1])[c(1, 2, 2, 1, 1)]y_plane<-range(-(nweeks:1))[c(1, 1, 2, 2, 1)]# convert into coordinate system of perspective plotplane<-trans3d(x_plane, y_plane, 0, res)lines(plane, col =2, lwd =1, lty=2)# Plot total site-specific effects (`pp+ps`)lapply(our_sites, \(x){ tpdt<-subset(pdt, Site==x) z_array<-array(tpdt$p, dim=c(D, T))# plot fitted valuespersp(x= lags_sp[-1],y=-(nweeks:1),z= z_array,col=rgb(0.5, 0.5, 0.5, 0),border=rgb(0.5, 0.5, 0.5, 0.2),theta=40, phi=30,zlim=range(pdt$p),xlab="Distance", ylab="Week", zlab="Effect",ticktype="detailed",main= x) -> res# define x and y values for the z = 0 plane x_plane<-range(lags_sp[-1])[c(1, 2, 2, 1, 1)] y_plane<-range(-(nweeks:1))[c(1, 1, 2, 2, 1)]# convert into coordinate system of perspective plot plane<-trans3d(x_plane, y_plane, 0, res)lines(plane, col =2, lwd =1, lty=2)})```> *Population-level SST coefficient function (green surface)*: at week -30 (front), the function is negative near the colonies (left) and gradually becomes null at the extreme of the distance range. This would suggest that early in the year (week beginning 1st Jan), the effect of SST on kittiwake productivity tends to be negative near the colony, i.e. higher SST tends to correlate with lower productivity, and no effect further away. Moving towards spring and then summer, the SST effect generally becomes null (or slightly negative) near the colonies and positive beyond ~ 150 km.> *Site-specific SST coefficient functions (all other panels, with transparent surfaces)*: the functions show are the full site-specific function, as they include both the population-level function and any site-specific deviation around it. Most sites show mostly minor deviations from the population-level pattern (qualitatively at least), but a few differ more substantially, e.g. Marwick Head, Noness, Row Head, Saltburn Cliffs, mainly over the temporal lag dimension.It is possible to visualize only the site deviations from the population-level effect, by replacing `tpdt$p` by `tpdt$ps` in the second part of the plotting code.### Model validationWe should look at traditional GAM diagnostics, using deviance residuals.```{r}par(mfrow=c(2, 2))gam.check(m_dts)abline(0, 1)```> These residuals diagnostics are broadly acceptable.When assuming linear effects of a predictor (here, SST), it's often worth checking for unwanted trends in the residuals against predictor values. With SST broken down into so many distinct predictors (here, 30 lags) panel plots using a sliding window of lags can an effective way of visualizing the patterns.```{r}m_dts_res<-data.frame(resid=residuals(m_dts), SST=as.vector(SSTm[-m_dts$na.action, ]),Dlag=as.vector(Dm[-m_dts$na.action, ]),Tlag=as.vector(Tm[-m_dts$na.action, ]))# residuals against spatial lagcoplot(resid ~ SST | Dlag, data= m_dts_res, panel= panel.smooth, number=12, lwd=3)```> No apparent trend in the moving averages in red (good news).```{r}# residuals against time lagcoplot(resid ~ SST | Tlag, data= m_dts_res, panel= panel.smooth, number=12, lwd=3)```> Both the mean and variance of SST increase, as we move away from winter (left to right, then bottom to top). The moving averages (red) suggest that there could be some non-linearity in the relationship with SST, which was not considered in this model.# SimulationsWe will work in the 1D case for this simulation, for simplicity.Loading a function to generate random 1D smooth functions, which will allow us to simulate the "true"/known effect (coefficient) of predictor vector $X$ measured over a series of $K$ lags $D$.Function name: `sim_spline_1D(k= 7, lambda= c(0.05, 0.005), inter= 0, x_l= 100)`Arguments:* `k`: spline basis size* `lambda`: a vector of length 2 specifying smoothing parameters 'lambda' for the 1D thin plate spline* `inter`: intercept value* `x_l`: number of x values a which to evaluate 1D smooth```{r, warning= F}require(mgcv)require(mvtnorm)sim_spline_1D<-function(k=7, lambda=c(0.05, 0.005), inter=0, x_l=100) {# Define the spatial domain x<-seq(0, 1, length.out= x_l) resp<-rnorm(x_l)# Open a null file connection to discard the 'jagam()' text output# Check the operating systemif (.Platform$OS.type =="unix") { null_device<-"/dev/null" } else { # Windows null_device<-"NUL" } con<-file(null_device, open="wt")# generate a template gam model object for JAGS to extract the relevant components jd<-jagam(resp ~s(x, bs="tp", k= k), file= con, diagonalize= F)close(con) S1<- jd$jags.data$S1 zero<- jd$jags.data$zero# penalty matrix K1<- S1[1:(k-1),1:(k-1)] * lambda[1] + S1[1:(k-1),k:(2*k-2)] * lambda[2]# simulate multivariate normal basis coefficients beta_sim<-c(inter, mvtnorm::rmvnorm(n=1, mean= zero[2:k], sigma= K1, method="chol"))# evaluate simulated function at x values fct_sim<- jd$jags.data$X %*% beta_simreturn(fct_sim)}# example# sim_1D<- sim_spline_1D(k= 7, lambda= c(0.05, 0.005), inter= 0, x_l= 100)# plot(sim_1D, type= "l")```Now, a function to simulate data from the model, given the known parameter values.Output values:* `X`: lagged predictor matrix* `Lag`: lag-encoding matrix* `tf`: true lagged-effect function* `Y`: response vector```{r}# function to simulate 1D-lagged processsim_lag_of_1D<-function(N=300, nlags=20, ngroups=10, residSD=1){# simulate time-varying predictor, where each column represents a time lag w.r.t. the observation X<-matrix(runif(N*nlags), N, nlags)# true shared coefficient function T_shared<-sim_spline_1D(x_l= nlags)# shared trend contribution to linear predictor LP_shared<- X %*% T_shared# generate ngroups in the data group<-sort(rep(1:ngroups, length.out= N)) X_group<-lapply(split(X, group), function(x) matrix(x, ncol= nlags))# true group-specific deviation from shared trend + random intercept T_group<-lapply(1:ngroups, function(x) sim_spline_1D(x_l= nlags))# standardize variances across lags T_group_sd<-apply(do.call(cbind, T_group), 1, sd) T_group<-lapply(T_group, function(x) x / T_group_sd)# apply shrinkage group_shrink<-abs(rnorm(ngroups, sd=1)) T_group<-mapply(`*`, T_group, group_shrink, SIMPLIFY= F)# group random effects group_RE<-rnorm(ngroups, sd=1)# group-specific contribution to linear predictor LP_group<-unlist(mapply(`%*%`, X_group, T_group, SIMPLIFY= F))# Linear predictor#Y<- rnorm(n= N, mean= LP_shared + # LP_group +# group_RE[group], # random group effect# sd= residSD) Y <- LP_shared + LP_group + group_RE[group] Y <- Y +rnorm(N, 0, sd=residSD) gg<-factor(paste0("G", group)) GG<-rep(gg, each= nlags)dim(GG)<-c(N, nlags)# index matrix Lag<-matrix(0:(nlags-1), N, nlags, byrow= T)list(X= X, Y= Y, ts= T_shared, tf=sapply(T_group, function(x) x + T_shared), Group= GG,group= gg,group_RE= group_RE,N= N,nlags= nlags,ngroups= ngroups,Lag= Lag)}```Let's simulate 3 random data sets from 3 different sets of random model parameters, and plot the estimates of $f(d)$ (labelled "f(Lag)") with their 95% confidence intervals (black), together with the true values (red). The x-axis shows $d$ (labelled "Lag").```{r}par(mfcol=c(2, 3))# set.seed(53) # for reproducibilityfor(i in1:3){ dat<-sim_lag_of_1D(N=800, nlags=20, ngroups=8, residSD=0.1) mod<-gam(Y ~s(group, bs="re") +s(Lag, by= X, k=ncol(dat$Lag)-1) +te(Lag, Group, by= X, bs=c("tp", "re"), k=c(ncol(dat$Lag)-1, dat$ngroups)),method="REML",data= dat) newdat<-cbind(expand.grid(Lag= dat$Lag[1, ], Group=factor(paste0("G", 1:dat$ngroups))),X=1) newdat$group<- newdat$Group predictions<-predict(mod, newdata= newdat, type="terms") newdat$f_est<-apply(predictions, 1, sum) +coef(mod)[1] newdat$s_est<- predictions[, 2] +coef(mod)[1] newdat$tf<-as.vector(dat$tf) + dat$group_RE[newdat$group] rng<-range(c(newdat$f_est, newdat$tf))matplot(dat$tf, type="l", xlab="Lag", ylab="f(Lag)", main=paste0("Simulation ", i, "\nTrue functions"), ylim= rng)lines(dat$ts, lwd=3)abline(h=0, lty=3, col=grey(0.6)) f_est<-matrix(newdat$f_est, dat$nlags, dat$ngroup)matplot(dat$Lag[1, ], f_est, type="l", xlab="Lag", ylab="f(Lag)", main=paste0("Simulation ", i, "\nEstimated functions"), ylim= rng)lines(newdat$Lag[1:dat$nlags], newdat$s_est[1:dat$nlags], lwd=3)abline(h=0, lty=3, col=grey(0.6))}```> The shared functions are well recovered but the group-specific curves aren't. We expect this is an error with the simulation code but haven't yet been able to identify it.# Proposed exercises* Level 1: repeat the analysis above (spatial and temporal lags of SST). * Level 2: fit a group effect in a previous model, e.g. for lagged effects of SST (temporal or spatial only) or sandeels (spatial lags).In all cases, pay attention to the structure of the model inputs (vectors and matrices) and take some time to reflect on the interpretation of the model outputs.