This vignette covers models where the response is a function of predictor values, measured at a collection (vector) of regular distance increments, which may represent distance in space (spatial lags), or in the past (time lags), for example.
The model assumes that the coefficient (effect) of the predictor varies smoothly with the distance at which it is measured.
This model may be relevant in scenarios where:
the response variable depends on environmental conditions experienced in the past (may be termed “memory”, “lagged” or “carry-over” effects, depending on contexts). Lags may or may not extend to present time.
the response variable depends on environmental conditions over a neighborhood (the “zone of influence” of these environmental factors).
the response variable depends on predictors measured over any ordered index of sorts (e.g., distance). A classic application is in spectrometry, where the whole series of fluorescence levels at increasing light frequencies can be used as predictor.
and typically, where the relative relevance of different lags/distances/indices for predicting the response is unknown and needs to be inferred from the data.
Mathematical description
For each observation \(i\), the linear predictor includes the additive effects of a vector predictor \(X_{i}\) consisting of values \(x_{ij}\) measured at a range of regular distances increments \(d_{ij}\) forming the distance vector \(D_i\). In typical applications, \(D_i\) is invariant between observations, so index \(i\) can be omitted.
Function \(f(d_j)\) acts as a coefficient for \(x_{ij}\), that varies smoothly with distance \(d_{j}\). The shape of \(f(d_j)\) is typically unknown and needs to be estimated from the data, so the function should have sufficient flexibility to ensure a good fit to the data, while being sufficiently constrained to avoid overfitting. In this tutorial we will represent \(f\) with penalized regression splines, since they meet these requirements and are easily implemented using standard software.
R implementation
The R implementation of the model, using package mgcv, is of the form:
Where y is a dataframe column with \(N\) observations, and D and X are both \(N \times J\) matrices, with the number of columns \(J\) corresponding to the number of distance classes over which predictor \(X\) was measured.
Matrix D encodes the actual distances values, with equal intervals and constant across rows (if this is not the case, appropriate integration weights should be applied). The units chosen for expressing \(D\) are arbitrary and do not affect the predictions of the model (only its interpretation).
The summation convention applied in mgcv means that when the data fed to the smooth terms are multi-column matrices, the sum of the function evaluation over all columns (after multiplication by the corresponding entry of any by= argument) is returned.
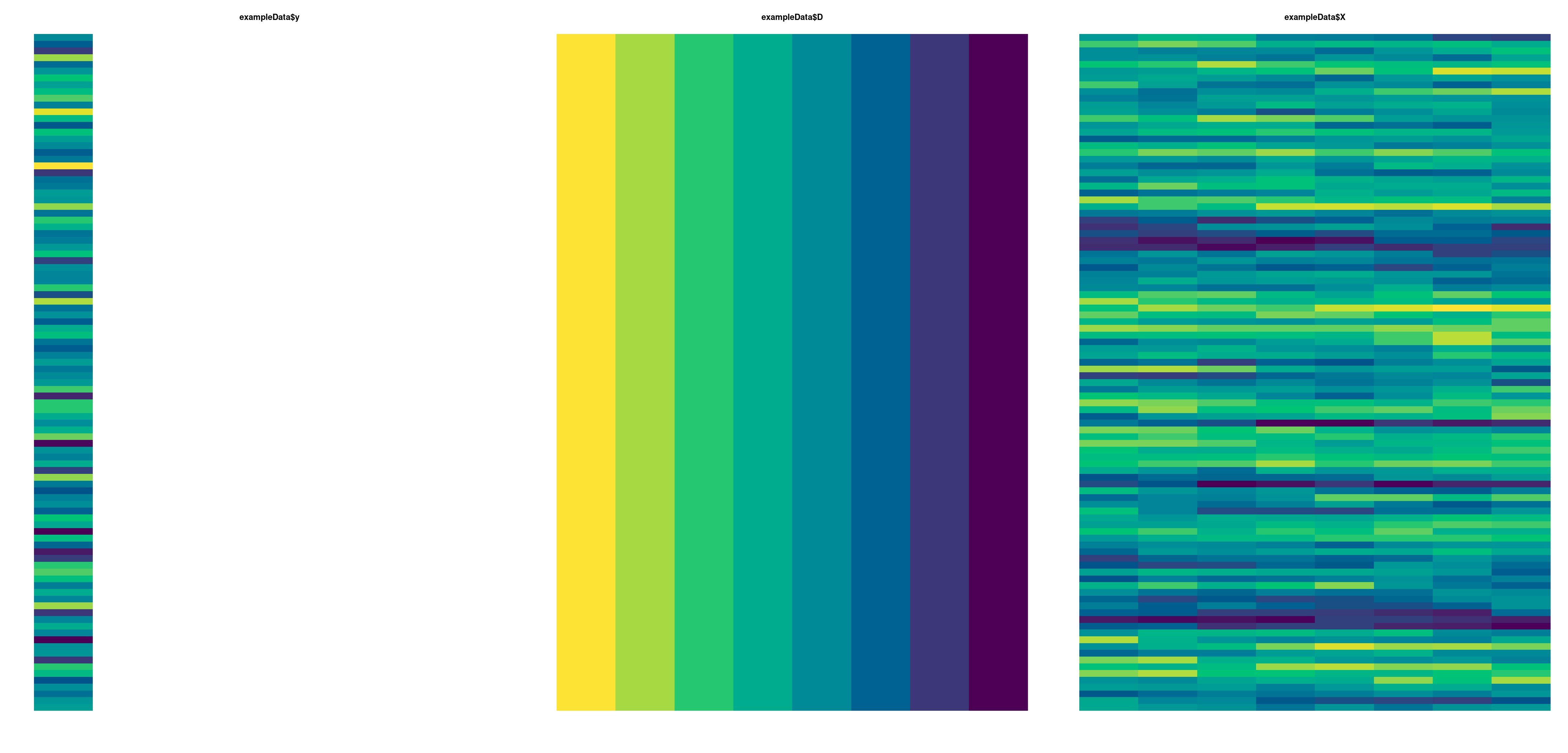
The input data should have the following structure (illustrative example with 8 distances and 100 observations):
y (response) is typically a single-column vector (may have two columns for binomial family or an arbitrary number for likelihoods that make use of this, such as multivariate normal).
D has one column per distance (index) value and is normally row-invariant.
X has same dimension as D and is NOT row-invariant. If there is correlation in the \(x_{ij}\) values between adjacent distance classes, rows of \(X\) will tend to display serial correlation patterns, as in the illustrative example above.
Further notes
This model belongs to the “signal regression” model family, where the profile of \(X\) values over the \(D\) increments forms a function \(x(d)\), called the “signal”.
Under typical circumstances (i.e., the \(d\) increments are regular and there is no missing value in \(X\)), the model is also a form of “distributed lag model”, where the effect of \(x\) has been constrained to be linear for any value of \(d\).
Illustration: analysis of kittiwake breeding success
The motivation for the model, its construction and interpretation are best shown by example. Background information about the kittiwake case study can be found in the introductory vignette (“1_Introduction”).
Specific research question
“Is there a (linear) effect of SST on kittiwake yearly breeding success and how does it change across time lags”
or
“How far back in time does SST value contribute to predicting yearly breeding success?”
A signal regression model with just temporal lags
A direct answer to the “Specific research question” can be given by a signal regression using SST values at suitable temporal lags, as predictors.
Here, we will use weekly SST values and assume that the effect of SST does not extend beyond 30 weeks (~ 6 months) in the past.
The SST satellite images would allow us to work at different time resolutions for SST, from daily to monthly values. A daily resolution (~ 200 values) wouldn’t be problematic for the analysis, but we wouldn’t expect such a fine resolution to be relevant for the biological processes involved, in our context. It would also incur a significant and unnecessary computational cost. At the other end, a monthly resolution for SST values would only give us 6 intervals, which may miss biologically relevant variation and limit the scope for fitting spline functions capable of accurately capturing the underlying “true” function (assuming it exists). A weekly resolution with 30 intervals, seems a reasonable trade-off.
For this example, we further assume that the influence of SST doesn’t extend further than 80 km from the breeding colony, and that the effect doesn’t vary over this distance range, so that SST values can be averaged over a 80 km radius.
Data preparation
# loading the data# depending on the configuration of# your system, one of these should worktry(load("kit_SST_sandeel.RData"), silent= T)try(load("../kit_SST_sandeel.RData"), silent= T)# we'll work with the smaller subset of 7 colonieskit1<- kit2[kit2$Site %in% kit_sub1, ]
Modelling parameters
# number of weeks to use as predictorsnweeks<-30# time lags (in weeks until Jun 30th)lags_ti<- nweeks:1
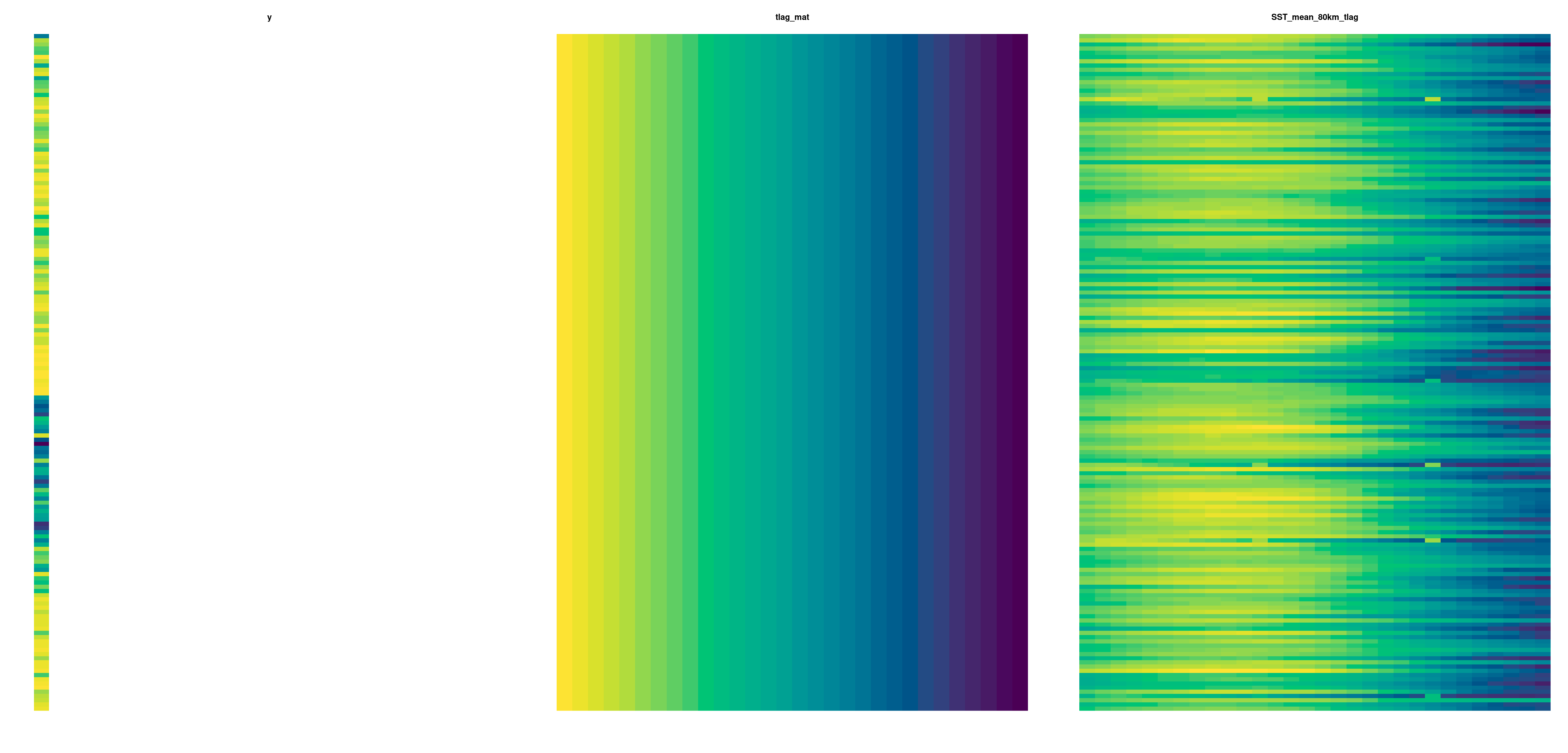
Preparing the predictor matrix (30 columns = weekly SST values). For each week, average SST calculated as the sum of SST values for all pixels within 80 km of the colony, divided by number of non-NA pixels, for the relevant colony and year.
# SST temporal lag matrix only, assuming fixed buffer @80 km# with SiteYears in rows and time lags (weeks since 1st Jan) in columnsSST_mean_80km_tlag<-t(SST_sum_buffer[, "80", kit1$SiteYear] / SST_noNA_buffer[, "80", kit1$SiteYear])# visualising the first 3 rows and 8 columns of the matrix:round(SST_mean_80km_tlag, 2)[1:3, 1:8]
Now, the corresponding temporal lag index matrix. We find convenient to annotate lags as negative week numbers, with -30 corresponding to the farthest week in time (w/c 1st Jan of that year) and -1 corresponding to the most recent. Other annotation systems can be used, without effect on the predictions of the model as long as intervals remain all equal.
tlag_mat<-t(matrix((-nweeks):(-1), nrow= nweeks, ncol=nrow(kit1)))# visualising the first 3 rows and 8 columns of the matrix:tlag_mat[1:3, 1:8]
Visual inputs check (yellow is lowest value, blue highest):
Fitting the model
An offset offset(log(AON + 1)) is used to standardise the number of chicks by the number of monitored nests (see Introduction vignette)
a site random effect is included to account for unknown variation in the mean breeding success between colonies: s(Site, bs= "re")
Data are assumed to follow a Tweedie distribution with a log link, which helps modelling overdispersion in the data.
SST values at each of 30 time lags are contained in matrix SST_mean_80km_tlag. Their effect on kittywake breeding success is assumed to vary smoothly with the time lag itself (encoded in matrix tlag_mat) and captured by the term s(tlag_mat, by= SST_mean_80km_tlag).
library(mgcv)
Loading required package: nlme
This is mgcv 1.9-3. For overview type 'help("mgcv-package")'.
The model summary suggests that there is clear variation in average breeding success between colonies, but the effect of SST within 80 km on kittiwake breeding success isn’t signifiant at any time lag.
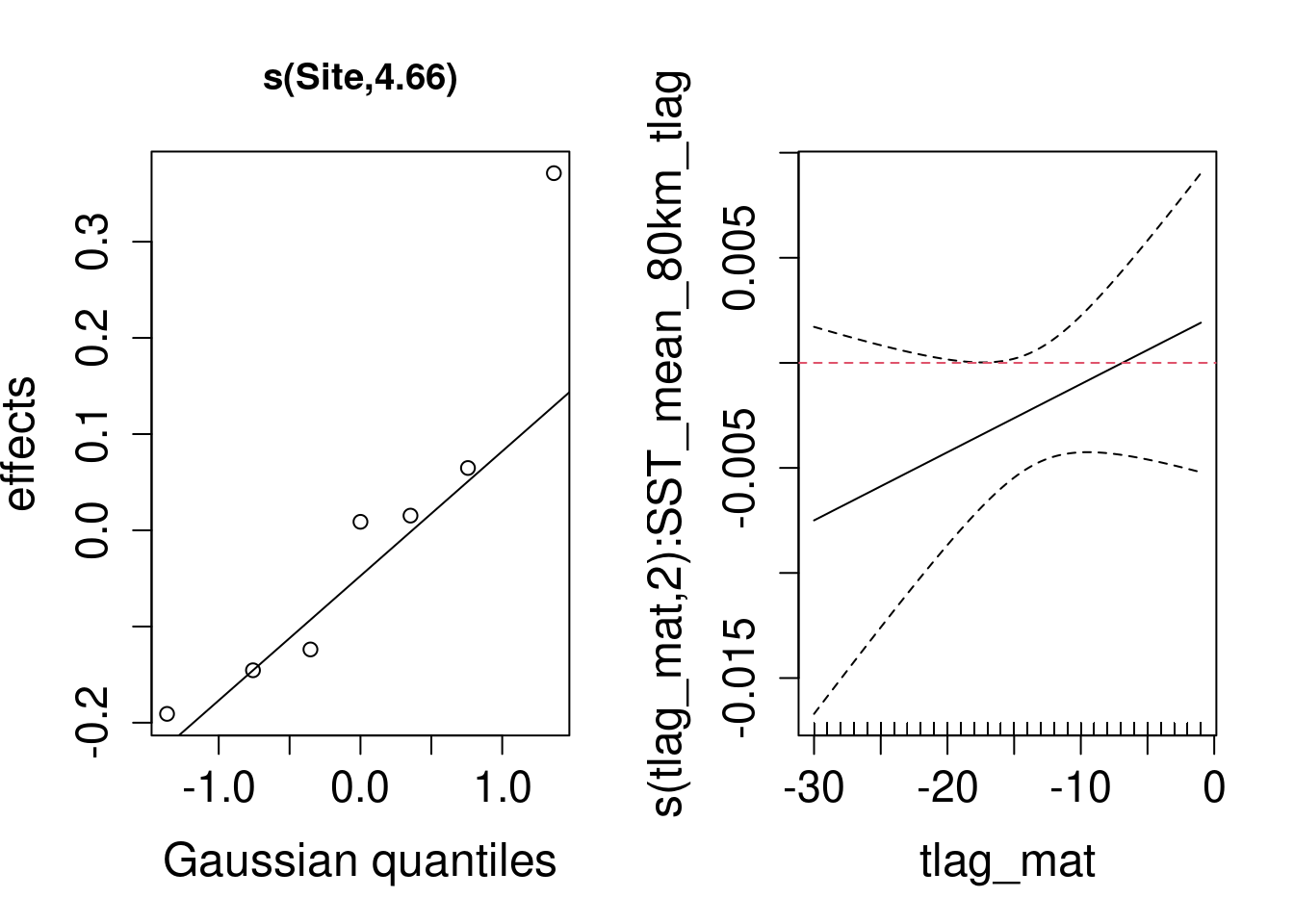
Plotting the estimated effects provides us with a richer interpretation:
The plot to the left shows a quantile-quantile plot of the random colony effects. With just 7 colonies, this is not terribly informative: some colonies do better than others (+/- 20% around the mean).
The plot to the right is the time lag function, of greatest interest to us. On the x-axis, is the time lag as we encoded it. The function of time lag acts as the lag-varying coefficient for the linear effect of SST at a given lag, so we care to know if the function is above or below zero (red dashed line), and so the effect of SST positive or negative, respectively, at a given time lag. The function at week -30 (left side) is negative, at around -0.07. This suggests that the effect of SST early in the year (week beginning 1st Jan) on kittiwake productivity tends to be negative, i.e. higher SST tends to correlate with lower productivity. Moving towards spring and then summer, the function of time lag gets closer to zero (red dashed line) and even maybe positive towards week 30 of the year (around 24th July, or time lag 0). Assuming these effects were significant, this would mean that SST’s influence on kittiwake productivity is most pronounced over winter, possibly by creating favourable conditions for kittiwake prey availability later in the season.
Model validation
In general, as we look further back in time the effect of past environmental conditions should eventually become irrelevant and close to zero. The estimated effect of SST being the largest (negative) at the furthest time lag (-30 weeks), could suggest that we did not consider lagged SST values far enough in the past.
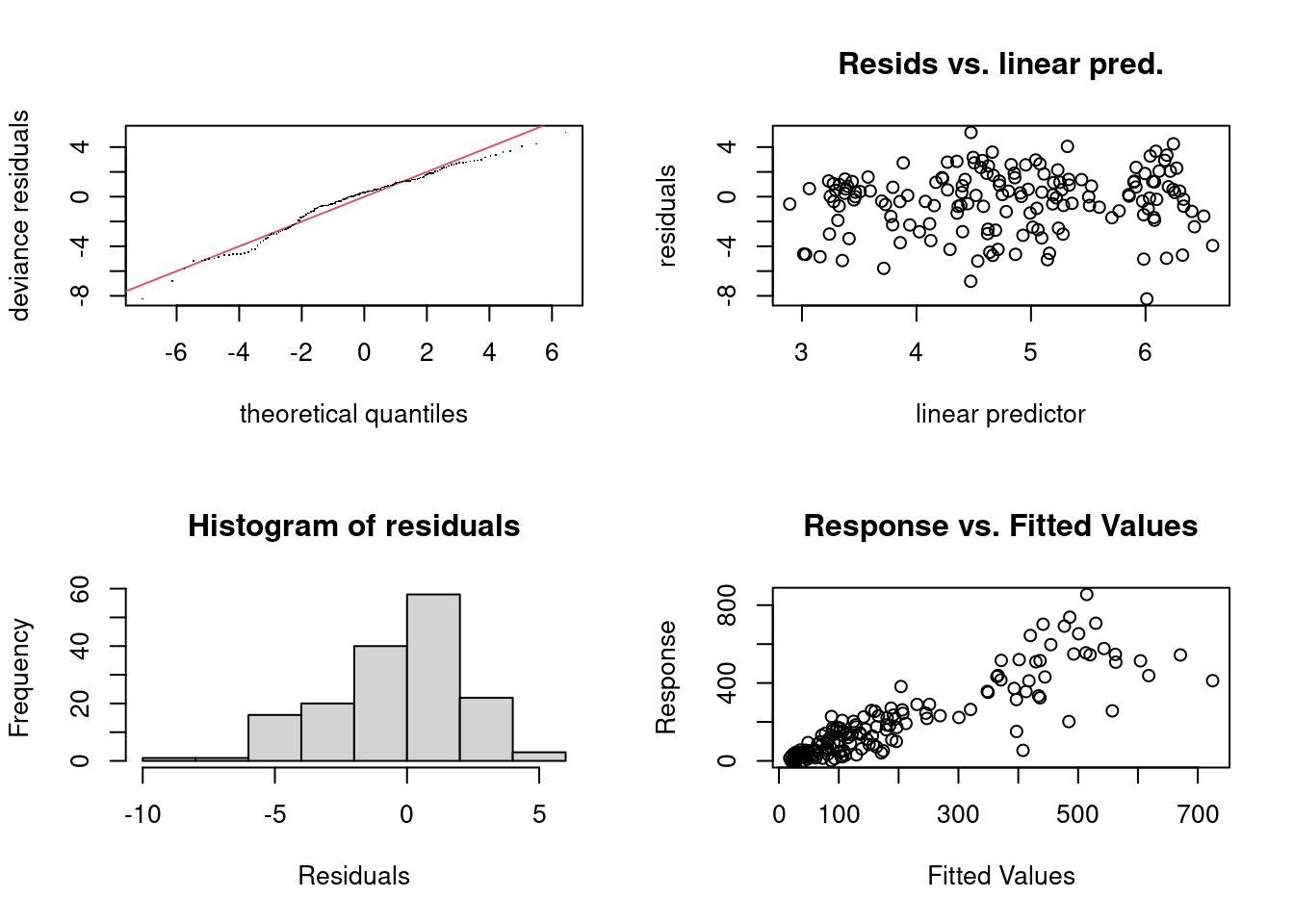
We should also look at traditional GAM diagnostics, using deviance residuals.
par(mfrow=c(2, 2))gam.check(m_t_VCR)
Method: REML Optimizer: outer newton
full convergence after 5 iterations.
Gradient range [-7.860433e-05,-9.891217e-06]
(score 894.3597 & scale 5.94197).
Hessian positive definite, eigenvalue range [7.858914e-05,187.4581].
Model rank = 18 / 18
Basis dimension (k) checking results. Low p-value (k-index<1) may
indicate that k is too low, especially if edf is close to k'.
k' edf k-index p-value
s(Site) 7.00 4.66 NA NA
s(tlag_mat):SST_mean_80km_tlag 10.00 2.00 NA NA
Overall the model is doing an okay job, but there is a long left tail to the residuals distribution, indicating that some observations are badly underpredicted. This model just isn’t an excellent fit for the data.
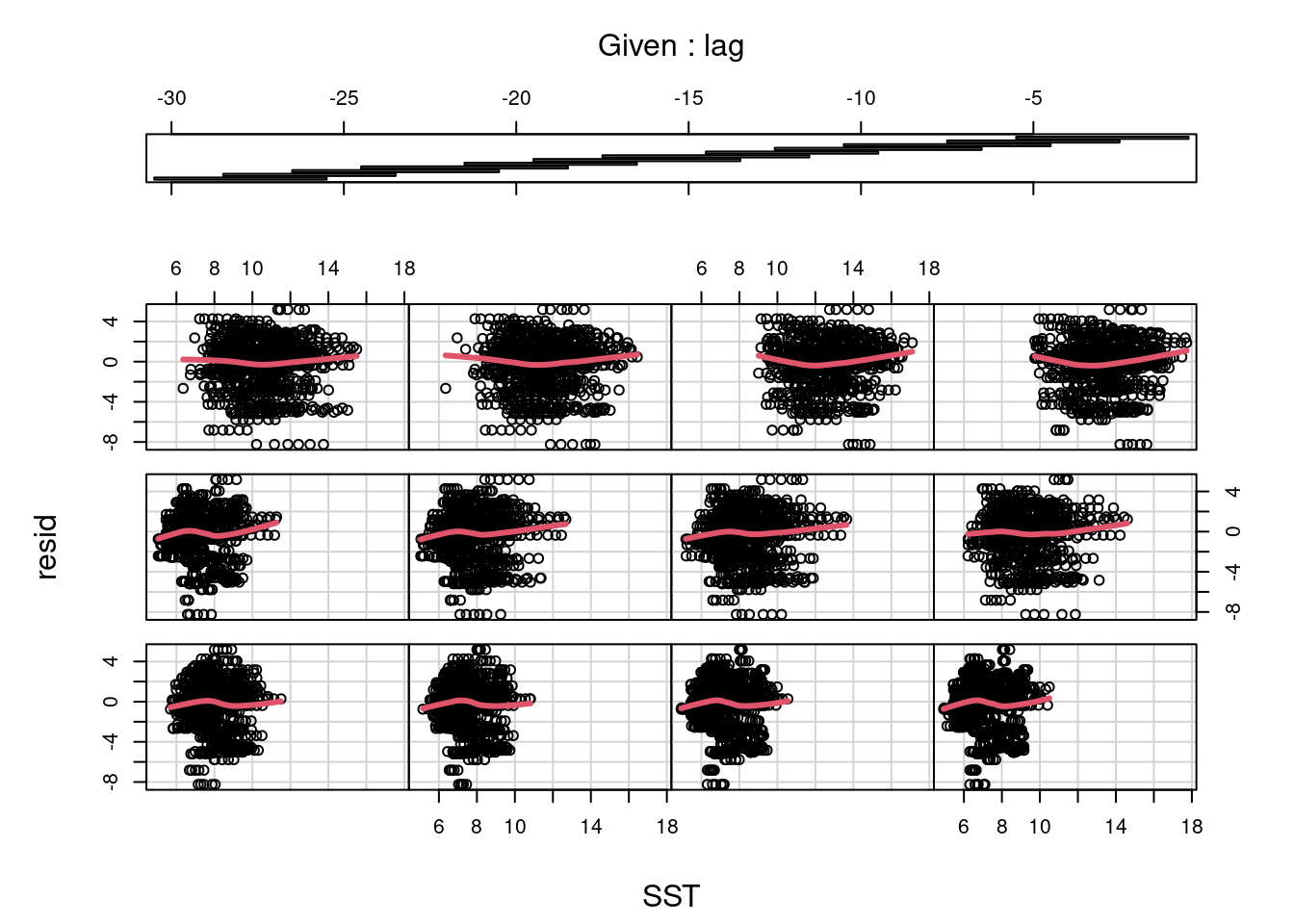
When assuming linear effects of a predictor (here, SST), it’s often worth checking for unwanted trends in the residuals against predictor values. With SST broken down into so many distinct predictors (here, 30 lags) panel plots using a sliding window of lags can an effective way of visualizing the patterns.
Both the mean and variance of SST increase, as we move away from winter (left to right, then bottom to top). The moving averages (red) suggest that there could be some non-linearity in the relationship with SST, which was not considered in this model.
Simulations
Loading a function to generate random 1D smooth functions, which will allow us to simulate the “true”/known effect (coefficient) of predictor vector \(X\) measured over a series of \(J\) lags (\(D\)).
lambda: a vector of length 2 specifying smoothing parameters ‘lambda’ for the 1D thin plate spline
inter: intercept value
x_l: number of x values a which to evaluate 1D smooth
require(mgcv)require(mvtnorm)
Loading required package: mvtnorm
# k: spline basis size# lambda: a vector of length 2 specifying smoothing parameters 'lambda' for the 1D thin plate spline# inter: intercept value# x_l: number of x values a which to evaluate 1D smoothsim_spline_1D<-function(k=7, lambda=c(0.05, 0.005), inter=0, x_l=100) {# Define the spatial domain x<-seq(0, 1, length.out= x_l) resp<-rnorm(x_l)# Open a null file connection to discard the 'jagam()' text output# Check the operating systemif (.Platform$OS.type =="unix") { null_device<-"/dev/null" } else { # Windows null_device<-"NUL" } con<-file(null_device, open="wt")# generate a template gam model object for JAGS to extract the relevant components jd<-jagam(resp ~s(x, bs="tp", k= k), file= con, diagonalize= F)close(con) S1<- jd$jags.data$S1 zero<- jd$jags.data$zero# penalty matrix K1<- S1[1:(k-1),1:(k-1)] * lambda[1] + S1[1:(k-1),k:(2*k-2)] * lambda[2]# simulate multivariate normal basis coefficients beta_sim<-c(inter, mvtnorm::rmvnorm(n=1, mean= zero[2:k], sigma= K1, method="chol"))# evaluate simulated function at x values fct_sim<- jd$jags.data$X %*% beta_simreturn(fct_sim)}# example# sim_1D<- sim_spline_1D(k= 7, lambda= c(0.05, 0.005), inter= 0, x_l= 100)# plot(sim_1D, type= "l")
Now, a function to simulate data from the model, given the known parameter values.
Output values:
X: lagged predictor matrix
Lag: lag-encoding matrix
tf: true lagged-effect function
Y: response vector
# function to simulate 1D-lagged processsim_lag_of_1D<-function(N=200, nlags=20, residSD=1){# simulate time-varying predictor, where each column represents a time lag w.r.t. the observation X<-matrix(runif(N*nlags), N, nlags)# true coefficient function tf<-sim_spline_1D(x_l= nlags)# observations Y<-rnorm(n= N, mean= X %*% tf, sd= residSD)# index matrix Lag<-matrix(0:(nlags-1), N, nlags, byrow= T)list(X= X, Y= Y, tf= tf, Lag= Lag)}
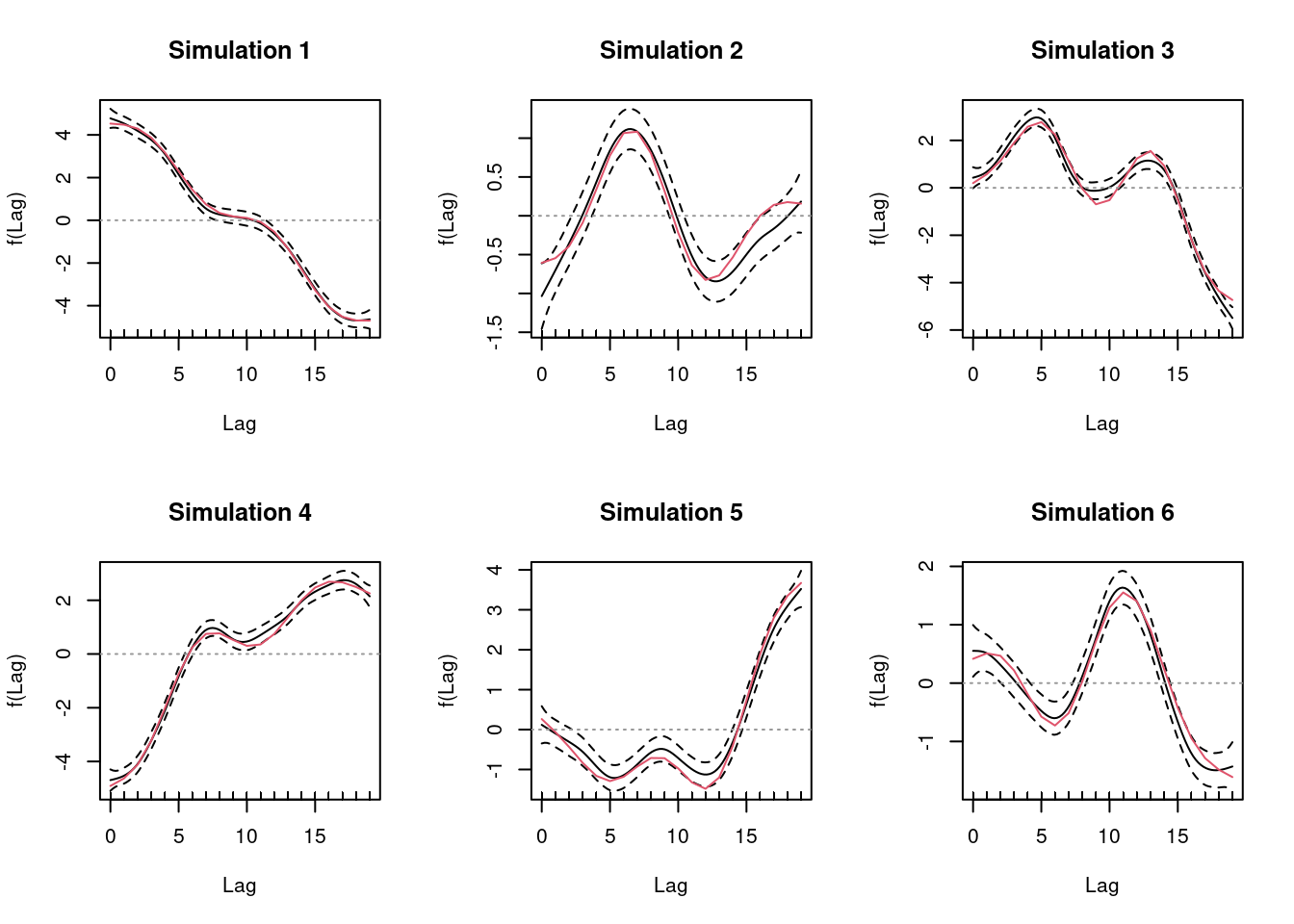
Let’s simulate 6 random data sets from 6 different sets of random model parameters, and plot the estimates of \(f(d)\) (labelled “f(Lag)”) with their 95% confidence intervals (black), together with the true values (red). The x-axis shows \(d\) (labelled “Lag”).
In all cases, \(f(d)\), the effect of \(X\) across lags \(D\) is well recovered by the model, with the true value most of the time contained in the 95% CI of the estimates.
Proposed exercises
Level 1: repeat the analysis above (temporal lag of SST). Parameters you could try and vary include a fixed distance buffer of your choice, and the coding of lag values.
Level 2: fit a model with 1D spatial lags, of either
sandeel predictor sandeel_mean_ring (use object kit_sub1 for subsetting it to match the rows of data set kit1)
SST (fixing the temporal range to your liking)
In all cases, pay attention to the structure of the model inputs (vectors and matrices) and take some time to reflect on the interpretation of the model outputs.
Source Code
---title: "[2-1] Distributed linear effects over 1D Lags"author:- name: Thomas Cornulier thomas.cornulier@bioss.ac.uk affiliation: "Biomathematics & Statistics Scotland (https://www.bioss.ac.uk/)"- name: Dave Miller dave.miller@bioss.ac.uk affiliation: "BioSS & UKCEH"date: "Last run on `r format(Sys.time(), '%d/%m/%Y')`"output: html_document: number_sections: true self_contained: true---# The modelThis vignette covers models where the response is a function of predictor values, measured at a collection (vector) of regular distance increments, which may represent distance in space (spatial lags), *or* in the past (time lags), for example.The model assumes that the coefficient (effect) of the predictor varies smoothly with the distance at which it is measured.This model may be relevant in scenarios where:- the response variable depends on environmental conditions experienced in the past (may be termed "memory", "lagged" or "carry-over" effects, depending on contexts). Lags may or may not extend to present time. - the response variable depends on environmental conditions over a neighborhood (the "zone of influence" of these environmental factors).- the response variable depends on predictors measured over any ordered index of sorts (e.g., distance). A classic application is in spectrometry, where the whole series of fluorescence levels at increasing light frequencies can be used as predictor.and typically, where the relative relevance of different lags/distances/indices for predicting the response is unknown and needs to be inferred from the data.## Mathematical descriptionFor each observation $i$, the linear predictor includes the additive effects of a vector predictor $X_{i}$ consisting of values $x_{ij}$ measured at a range of regular distances increments $d_{ij}$ forming the distance vector $D_i$. In typical applications, $D_i$ is invariant between observations, so index $i$ can be omitted.The model is of the form:$$\mathbb{E}(y_i) = g^{-1}\left( \beta_0 + \sum_j f(d_{j}) x_{ij}\right)$$or in compact vector form,$$\mathbb{E}(y_i) = g^{-1}\left( \beta_0 + X_{i} f(D)\right)$$Function $f(d_j)$ acts as a coefficient for $x_{ij}$, that varies smoothly with distance $d_{j}$. The shape of $f(d_j)$ is typically unknown and needs to be estimated from the data, so the function should have sufficient flexibility to ensure a good fit to the data, while being sufficiently constrained to avoid overfitting. In this tutorial we will represent $f$ with penalized regression splines, since they meet these requirements and are easily implemented using standard software.## R implementationThe R implementation of the model, using package `mgcv`, is of the form:`thisModel<- gam(y ~ s(D, by= X), data= exampleData)`Where `y` is a dataframe column with $N$ observations, and `D` and `X` are both $N \times J$ matrices, with the number of columns $J$ corresponding to the number of distance classes over which predictor $X$ was measured. Matrix `D` encodes the actual distances values, with equal intervals and constant across rows (if this is not the case, appropriate integration weights should be applied). The units chosen for expressing $D$ are arbitrary and do not affect the predictions of the model (only its interpretation).The summation convention applied in `mgcv` means that when the data fed to the smooth terms are multi-column matrices, the sum of the function evaluation over all columns (after multiplication by the corresponding entry of any `by=` argument) is returned.The input data should have the following structure (illustrative example with 8 distances and 100 observations):(here showing only the first 4 observations)```{r, echo= F}nr<-100nc<-8exampleData<-list(y=rnorm(nr, 2.5, 1),D=matrix(0:(nc-1), nr, nc, byrow= T) *5,X=matrix(arima.sim(n= nr*nc, model=list(ar=0.85)), nr, nc, byrow= T))colnames(exampleData$D)<-paste0("D", 1:nc)colnames(exampleData$X)<-paste0("X_D", 1:nc)exampleData<-lapply(exampleData, FUN=function(x) round(x, 2))``````{r}head(exampleData$y, n=4)head(exampleData$D, n=4)head(exampleData$X, n=4)```Visually (yellow is lowest value, blue highest):```{r, echo= F, fig.width= 25, fig.height= 12}par(mfrow=c(1, 3), bty="n", xaxt ="n", yaxt ="n")image(t(cbind(exampleData$y, matrix(NA, nr, nc-1))), col=rev(hcl.colors(64)), main="exampleData$y")image(t(exampleData$D), col=rev(hcl.colors(64)), main="exampleData$D")image(t(exampleData$X), col=rev(hcl.colors(64)), main="exampleData$X")```Key features:* `y` (response) is typically a single-column vector (may have two columns for binomial family or an arbitrary number for likelihoods that make use of this, such as multivariate normal).* `D` has one column per distance (index) value and is normally row-invariant.* `X` has same dimension as `D` and is *NOT* row-invariant. If there is correlation in the $x_{ij}$ values between adjacent distance classes, rows of $X$ will tend to display serial correlation patterns, as in the illustrative example above.## Further notesThis model belongs to the "signal regression" model family, where the profile of $X$ values over the $D$ increments forms a function $x(d)$, called the "signal".Under typical circumstances (i.e., the $d$ increments are regular and there is no missing value in $X$), the model is also a form of "distributed lag model", where the effect of $x$ has been constrained to be linear for any value of $d$.# Illustration: analysis of kittiwake breeding successThe motivation for the model, its construction and interpretation are best shown by example. Background information about the kittiwake case study can be found in the introductory vignette ("1_Introduction").## Specific research question"Is there a (linear) effect of SST on kittiwake yearly breeding success and how does it change across time lags"or"How far back in time does SST value contribute to predicting yearly breeding success?"### A signal regression model with just temporal lagsA direct answer to the "Specific research question" can be given by a signal regression using SST values at suitable temporal lags, as predictors.Here, we will use weekly SST values and assume that the effect of SST does not extend beyond 30 weeks (~ 6 months) in the past.> The SST satellite images would allow us to work at different time resolutions for SST, from daily to monthly values. A daily resolution (~ 200 values) wouldn't be problematic for the analysis, but we wouldn't expect such a fine resolution to be relevant for the biological processes involved, in our context. It would also incur a significant and unnecessary computational cost. At the other end, a monthly resolution for SST values would only give us 6 intervals, which may miss biologically relevant variation and limit the scope for fitting spline functions capable of accurately capturing the underlying "true" function (assuming it exists). A weekly resolution with 30 intervals, seems a reasonable trade-off.For this example, we further assume that the influence of SST doesn't extend further than 80 km from the breeding colony, and that the effect doesn't vary over this distance range, so that SST values can be averaged over a 80 km radius.### Data preparation```{r, warning= F}# loading the data# depending on the configuration of# your system, one of these should worktry(load("kit_SST_sandeel.RData"), silent= T)try(load("../kit_SST_sandeel.RData"), silent= T)# we'll work with the smaller subset of 7 colonieskit1<- kit2[kit2$Site %in% kit_sub1, ]```Modelling parameters```{r}# number of weeks to use as predictorsnweeks<-30# time lags (in weeks until Jun 30th)lags_ti<- nweeks:1```Preparing the predictor matrix (30 columns = weekly SST values).For each week, average SST calculated as the sum of SST values for all pixels within 80 km of the colony, divided by number of non-NA pixels, for the relevant colony and year.```{r}# SST temporal lag matrix only, assuming fixed buffer @80 km# with SiteYears in rows and time lags (weeks since 1st Jan) in columnsSST_mean_80km_tlag<-t(SST_sum_buffer[, "80", kit1$SiteYear] / SST_noNA_buffer[, "80", kit1$SiteYear])# visualising the first 3 rows and 8 columns of the matrix:round(SST_mean_80km_tlag, 2)[1:3, 1:8]```Now, the corresponding temporal lag index matrix. We find convenient to annotate lags as negative week numbers, with -30 corresponding to the farthest week in time (w/c 1st Jan of that year) and -1 corresponding to the most recent. Other annotation systems can be used, without effect on the predictions of the model as long as intervals remain all equal.```{r}tlag_mat<-t(matrix((-nweeks):(-1), nrow= nweeks, ncol=nrow(kit1)))# visualising the first 3 rows and 8 columns of the matrix:tlag_mat[1:3, 1:8]```Visual inputs check (yellow is lowest value, blue highest):```{r, echo= F, fig.width= 25, fig.height= 12}par(mfrow=c(1, 3), bty="n", xaxt ="n", yaxt ="n")image(t(cbind(kit1$Fledg, matrix(NA, nrow(kit1), nweeks))), col=rev(hcl.colors(64)), main="y")image(t(tlag_mat), col=rev(hcl.colors(64)), main="tlag_mat")image(t(SST_mean_80km_tlag), col=rev(hcl.colors(64)), main="SST_mean_80km_tlag")```### Fitting the model* An offset `offset(log(AON + 1))` is used to standardise the number of chicks by the number of monitored nests (see Introduction vignette)* a site random effect is included to account for unknown variation in the mean breeding success between colonies: `s(Site, bs= "re")`* Data are assumed to follow a Tweedie distribution with a log link, which helps modelling overdispersion in the data.SST values at each of 30 time lags are contained in matrix `SST_mean_80km_tlag`. Their effect on kittywake breeding success is assumed to vary smoothly with the time lag itself (encoded in matrix `tlag_mat`) and captured by the term `s(tlag_mat, by= SST_mean_80km_tlag)`.```{r}library(mgcv)m_t_VCR<-gam(Fledg ~offset(log(AON +1)) +s(Site, bs="re") +s(tlag_mat, by= SST_mean_80km_tlag), data= kit1, family=tw(),method="REML")```### Model output & interpretation```{r}summary(m_t_VCR)```> The model summary suggests that there is clear variation in average breeding success between colonies, but the effect of SST within 80 km on kittiwake breeding success isn't signifiant at any time lag.Plotting the estimated effects provides us with a richer interpretation:```{r}par(mfrow=c(1, 2), cex.axis=1.4, cex.lab=1.5)plot(m_t_VCR)abline(h=0, lty=2, col=2)```> The plot to the left shows a quantile-quantile plot of the random colony effects. With just 7 colonies, this is not terribly informative: some colonies do better than others (+/- 20% around the mean). > The plot to the right is the time lag function, of greatest interest to us. On the x-axis, is the time lag as we encoded it. The function of time lag acts as the lag-varying coefficient for the linear effect of SST at a given lag, so we care to know if the function is above or below zero (red dashed line), and so the effect of SST positive or negative, respectively, at a given time lag. The function at week -30 (left side) is negative, at around -0.07. This suggests that the effect of SST early in the year (week beginning 1st Jan) on kittiwake productivity tends to be negative, i.e. higher SST tends to correlate with lower productivity. Moving towards spring and then summer, the function of time lag gets closer to zero (red dashed line) and even maybe positive towards week 30 of the year (around 24th July, or time lag 0). Assuming these effects were significant, this would mean that SST's influence on kittiwake productivity is most pronounced over winter, possibly by creating favourable conditions for kittiwake prey availability later in the season.### Model validationIn general, as we look further back in time the effect of past environmental conditions should eventually become irrelevant and close to zero. The estimated effect of SST being the largest (negative) at the furthest time lag (-30 weeks), could suggest that we did not consider lagged SST values far enough in the past.We should also look at traditional GAM diagnostics, using deviance residuals.```{r}par(mfrow=c(2, 2))gam.check(m_t_VCR)```> Overall the model is doing an okay job, but there is a long left tail to the residuals distribution, indicating that some observations are badly underpredicted. This model just isn't an excellent fit for the data.When assuming linear effects of a predictor (here, SST), it's often worth checking for unwanted trends in the residuals against predictor values. With SST broken down into so many distinct predictors (here, 30 lags) panel plots using a sliding window of lags can an effective way of visualizing the patterns.```{r}m_t_VCR_res<-data.frame(resid=residuals(m_t_VCR), SST=as.vector(SST_mean_80km_tlag),lag=rep((-nweeks):(-1), each=nrow(kit1)))coplot(resid ~ SST | lag, data= m_t_VCR_res, panel= panel.smooth, number=12, lwd=3)```> Both the mean and variance of SST increase, as we move away from winter (left to right, then bottom to top). The moving averages (red) suggest that there could be some non-linearity in the relationship with SST, which was not considered in this model.# SimulationsLoading a function to generate random 1D smooth functions, which will allow us to simulate the "true"/known effect (coefficient) of predictor vector $X$ measured over a series of $J$ lags ($D$).Function name: `sim_spline_1D(k= 7, lambda= c(0.05, 0.005), inter= 0, x_l= 100)`Arguments:* `k`: spline basis size* `lambda`: a vector of length 2 specifying smoothing parameters 'lambda' for the 1D thin plate spline* `inter`: intercept value* `x_l`: number of x values a which to evaluate 1D smooth```{r, warning= F}require(mgcv)require(mvtnorm)# k: spline basis size# lambda: a vector of length 2 specifying smoothing parameters 'lambda' for the 1D thin plate spline# inter: intercept value# x_l: number of x values a which to evaluate 1D smoothsim_spline_1D<-function(k=7, lambda=c(0.05, 0.005), inter=0, x_l=100) {# Define the spatial domain x<-seq(0, 1, length.out= x_l) resp<-rnorm(x_l)# Open a null file connection to discard the 'jagam()' text output# Check the operating systemif (.Platform$OS.type =="unix") { null_device<-"/dev/null" } else { # Windows null_device<-"NUL" } con<-file(null_device, open="wt")# generate a template gam model object for JAGS to extract the relevant components jd<-jagam(resp ~s(x, bs="tp", k= k), file= con, diagonalize= F)close(con) S1<- jd$jags.data$S1 zero<- jd$jags.data$zero# penalty matrix K1<- S1[1:(k-1),1:(k-1)] * lambda[1] + S1[1:(k-1),k:(2*k-2)] * lambda[2]# simulate multivariate normal basis coefficients beta_sim<-c(inter, mvtnorm::rmvnorm(n=1, mean= zero[2:k], sigma= K1, method="chol"))# evaluate simulated function at x values fct_sim<- jd$jags.data$X %*% beta_simreturn(fct_sim)}# example# sim_1D<- sim_spline_1D(k= 7, lambda= c(0.05, 0.005), inter= 0, x_l= 100)# plot(sim_1D, type= "l")```Now, a function to simulate data from the model, given the known parameter values.Output values:* `X`: lagged predictor matrix* `Lag`: lag-encoding matrix* `tf`: true lagged-effect function* `Y`: response vector```{r}# function to simulate 1D-lagged processsim_lag_of_1D<-function(N=200, nlags=20, residSD=1){# simulate time-varying predictor, where each column represents a time lag w.r.t. the observation X<-matrix(runif(N*nlags), N, nlags)# true coefficient function tf<-sim_spline_1D(x_l= nlags)# observations Y<-rnorm(n= N, mean= X %*% tf, sd= residSD)# index matrix Lag<-matrix(0:(nlags-1), N, nlags, byrow= T)list(X= X, Y= Y, tf= tf, Lag= Lag)}```Let's simulate 6 random data sets from 6 different sets of random model parameters, and plot the estimates of $f(d)$ (labelled "f(Lag)") with their 95% confidence intervals (black), together with the true values (red). The x-axis shows $d$ (labelled "Lag").```{r}par(mfrow=c(2, 3))set.seed(53) # for reproducibilityfor(i in1:6){ dat<-sim_lag_of_1D(N=200, nlags=20, residSD=1) mod<-gam(Y ~s(Lag, by= X, k=ncol(dat$Lag)-1), data= dat)plot(mod, se=1.96, main=paste("Simulation", i), ylab="f(Lag)")lines(0:(ncol(dat$Lag)-1), dat$tf, col=2)abline(h=0, lty=3, col=grey(0.6))}```> In all cases, $f(d)$, the effect of $X$ across lags $D$ is well recovered by the model, with the true value most of the time contained in the 95% CI of the estimates.# Proposed exercises* Level 1: repeat the analysis above (temporal lag of SST). Parameters you could try and vary include a fixed distance buffer of your choice, and the coding of lag values.* Level 2: fit a model with 1D spatial lags, of either * sandeel predictor `sandeel_mean_ring` (use object `kit_sub1` for subsetting it to match the rows of data set `kit1`) * SST (fixing the temporal range to your liking)In all cases, pay attention to the structure of the model inputs (vectors and matrices) and take some time to reflect on the interpretation of the model outputs.